
-
Kubernetes扩容到7,500节点的历程
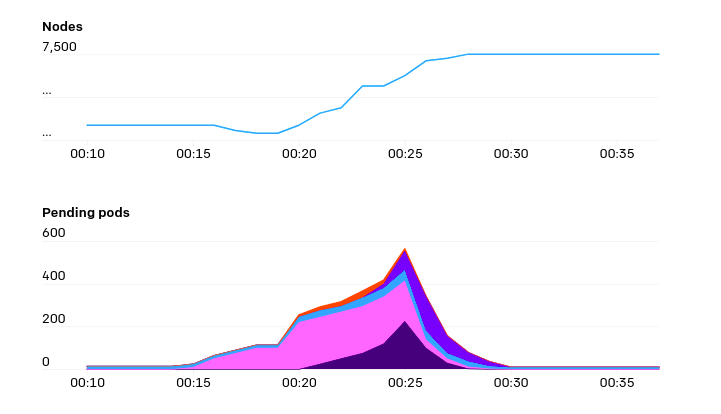
自发布上一篇《扩容到2,500个节点》(https://openai.com/blog/scaling-kubernetes-to-2500-nodes/)的文章以来,我们一直在扩容我们的基础架构以满足研究人员的需求,在这个过程中,我们学到了很多额外的经验教训。这篇文章总结了这些经验,以便Kubernetes社区中的其他人可以从中受益,并且以我们仍然面临的问题为结尾,接下来我们的首要任务也是要解决这些问题。
我们的工作描述
在我们深入本文之前,描述一下我们的工作内容是很重要的。我们使用Kubernetes运行的应用程序和硬件与您在典型公司可能遇到的情况有很大不同。我们的问题和相应的解决方案可能与您的场景匹配,也可能不匹配!
大型机器学习作业跨越多个节点,当它可以访问每个节点上的所有硬件资源时,它的运行效率最高。这允许gpu使用NVLink直接交叉通信,或者gpu使用GPUDirect直接与NIC通信。因此,对于我们的大多工作负载,一个pod占据了整个节点。NUMA、CPU或PCIE资源争用不是我们调度的因素。碎片化对我们而言并也不是常见问题。我们当前的集群有充分的带宽,因此我们也不用去考虑网络拓扑结构问题。所有这些都意味着,虽然我们有很多节点,但调度程序的压力相对较小。
也就是说,一项新工作可能包含数百个一次性创建的pod,此时对kube-scheduler的压力会很大,但是,然后就会恢复到相对较低的利用率。
我们最大的作业运行MPI,作业中的所有pod都参与一个MPI通信。如果任何一个参与的pod死亡,整个作业将停止,需要重新启动。作业检查点会定期执行,重新启动时从最后一个检查点恢复。因此,我们认为pods是半状态的,被杀死的pods可以被替换,工作可以继续,但是这样做是破坏性的,应将其降至最低限度。
我们并不完全依赖Kubernetes进行负载均衡。我们的HTTPS流量很少,不需要进行A/B测试,蓝/绿或金丝雀发布。Pod通过SSH,而不是服务端点,通过MPI在Pod IP地址上直接相互通信。服务“发现”是有限的;我们只是在作业启动时一次性查找哪些pod正在参与MPI。
所有作业与Blob存储交互。它们通常直接从Blob存储读写数据,或将其缓存到更快的本地临时磁盘。我们同时也有一些PersistentVolumes,但是blob存储有更大的可伸缩性,并且不需要较慢的detach/attach操作。
最后,我们的工作是从基础开始的,这意味着工作负载本身在不断变化。尽管超级计算团队努力提供我们所认为的满足“生产”能力水平的计算基础架构,但在该集群上运行的应用程序寿命很短,开发人员快速迭代。任何时候都有可能出现新的使用方式,这挑战了我们对未来趋势的预测。我们需要一个可持续发展的系统,该系统还可以让我们在事情发生变化时迅速做出响应。
网络
随着集群中节点和Pod数量的增加,我们发现Flannel难以满足所需的网络吞吐量。我们转而使用native pod网络技术,使用Azure VMSSes和对应的CNI插件进行IP配置。这使我们能够在Pod上获得主机级别的网络吞吐量。
我们转而使用基于别名的IP地址的另一个原因是,在我们最大的集群上,任何时候都可能有大约200000个IP地址正在使用。当我们测试基于路由的pod网络时,我们发现可以有效使用的路由数量存在明显的限制。
避免封装会增加对基础SDN或路由引擎的需求,但它会使我们的网络设置变得简单。无需任何其他适配器即可添加VPN或隧道。我们不必担心数据包碎片,因为网络的某些部分的MTU较低。网络策略和流量监控非常简单;数据包的源和目的地都很明确。
我们在主机上使用iptables标记来跟踪每个命名空间和pod的网络资源使用情况。这使研究人员可以可视化网络使用模式。特别是,由于我们的很多实验都有不同的Internet和Pod内部通信模式,因此这对排查可能出现瓶颈的位置通常很有用。
iptables
mangle规则可用于标记符合特定条件的数据包。以下是我们用来检测流量是内部流量还是互联网流量的规则。同时也可以看到FORWARD规则转发规则是来自pods的流量与来自主机的和输出流量的对比:iptables -t mangle -A INPUT ! -s 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-in" iptables -t mangle -A FORWARD ! -s 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-in" iptables -t mangle -A OUTPUT ! -d 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-out" iptables -t mangle -A FORWARD ! -d 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-out"
标记后,iptables将启动计数器来跟踪与此规则匹配的字节数和数据包数。您可以使用iptables命令本身查看这些计数器:
% iptables -t mangle -L -v Chain FORWARD (policy ACCEPT 50M packets, 334G bytes) pkts bytes target prot opt in out source destination .... 1253K 555M all -- any any anywhere !10.0.0.0/8 /* iptables-exporter openai traffic=internet-out */ 1161K 7937M all -- any any !10.0.0.0/8 anywhere /* iptables-exporter openai traffic=internet-in */
我们使用一个名为iptables-exporter(https://github.com/madron/iptables-exporter/)的开源Prometheus exporter,然后将其部署到我们的监视系统中。这是一种监控符合各种不同类型数据包的简单方法。
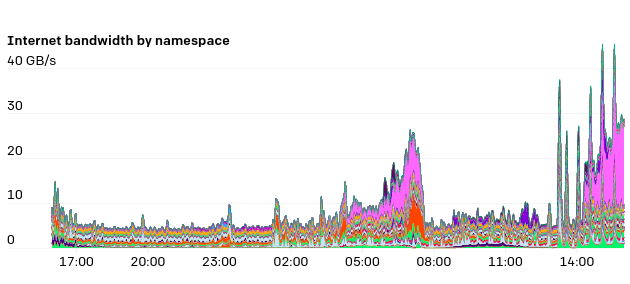
我们的网络模型的一个独特方面是,我们向研究人员公开了节点,pod和服务网络。我们有一个中心辐射网络模型,并使用本机节点和Pod CIDR来路由该流量。研究人员连接到中心,然后从那里可以访问任何单个集群。但是集群本身无法相互通信。这样可确保群集保持隔离状态,同时没有跨群集的依赖关系会破坏故障隔离。
我们使用“ NAT”主机来转换服务网络CIDR,以处理来自群集外部的流量。这种设置使我们的研究人员在选择实验方式和选择哪种网络配置时具有极大的灵活性。
API服务器
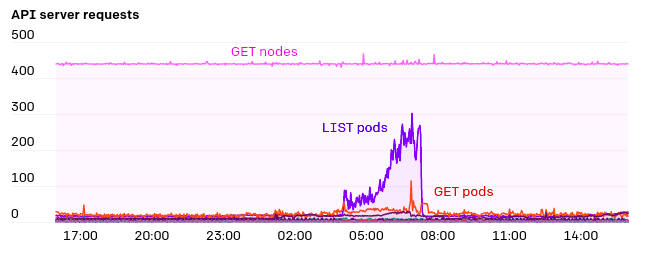
Kubernetes API服务器和etcd是集群健康运行的关键组件,因此我们特别关注这些系统的压力。我们使用kube-prometheus(https://github.com/coreos/kube-prometheus)提供的Grafana仪表盘,以及其他内部仪表盘。我们发现,在API服务器上HTTP状态码429(过多请求)和5xx(服务端错误)的告警速率是很有用的,通过他们能得知当前的kubernetns集群的压力。
虽然有些人在kube中运行API服务器,但我们是在集群之外运行它们的。etcd和API服务器都在各自的专用节点上运行。我们最大的集群运行5个API服务器和5个etcd节点,以分散负载,并在出现故障时将影响降至最低。自从我们在上一篇博文(https://openai.com/blog/scaling-kubernetes-to-2500-nodes/)中将Kubernetes分解成自己的etcd集群以来,我们在etcd方面没有遇到明显的问题。API服务器是无状态的,通常很容易在自愈实例组或scaleset中运行。我们还没有尝试构建etcd集群的自愈自动化,因为该事件非常罕见。
API服务器会占用相当大的内存,并且会随着群集中节点的数量线性扩展。对于有7500个节点的集群,我们观察到每个API服务器最多使用70GB的heap,所以幸运的是,这在未来的硬件能力范围内应该可以继续保持正常运行。
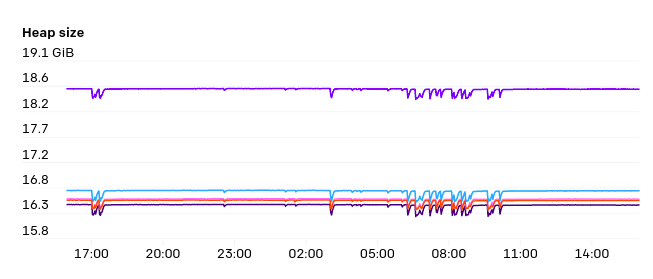
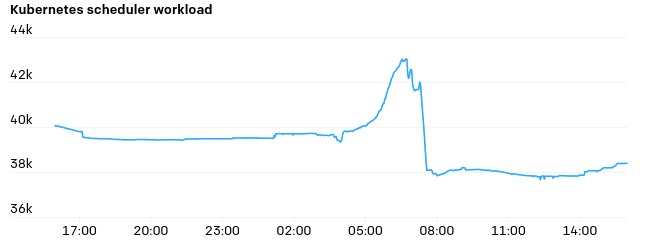
API服务器的一大压力是endpoint上的监空。有一些服务,例如“kubelet”和“node exporter”,集群中的每个节点都是这些服务的成员。当从集群中添加或删除节点时,将触发监控。而且由于每个节点本身通常都通过kube-proxy监控kubelet服务,因此这些响应所需的带宽将是N^2 ,非常庞大,偶尔甚至会达到1GB/s或更高。EndpointSlices是在Kubernetes 1.17中推出的,它带来了巨大的改善,它使负载降低了1000倍。
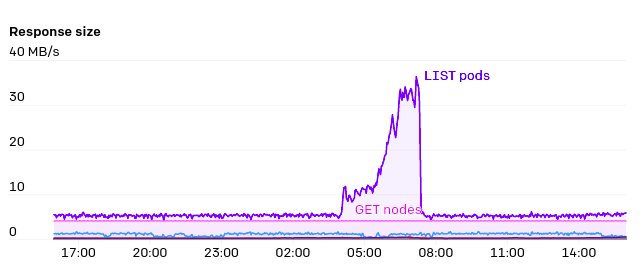
一般来说,我们比较关注所有随集群大小扩展的API服务器请求。我们尽量避免DaemonSet与API服务器交互。如果确实需要这样做,那么引入中间缓存服务(例如Datadog Cluster Agent)似乎是避免集群瓶颈的一个好的方式。
随着群集的增长,我们对群集的实际自动缩放操作将减少。但是当一次自动缩放过多时,我们有时会遇到麻烦。当新节点加入集群时,会生成很多请求,并且一次添加数百个节点可能会使API服务器容量过载。即使只需几秒钟就可以消除这种情况,这有助于避免停机。
Prometheus和Grafana的监控指标
我们使用Prometheus收集监控指标,并使用Grafana进行图形展示以及告警。我们首先部署,它收集各种各样的指标来用于可视化仪表板配置。随着时间的推移,我们添加了很多自己的仪表板,指标和告警。
随着我们添加越来越多的节点,我们对Prometheus收集的大量指标感到困惑。尽管kube-prometheus提供了很多有用的数据,但其中一些我们实际上从未使用过,而有些则过于精细而无法有效地收集,存储和查询。我们使用Prometheus规则(https://prometheus.io/docs/prometheus/latest/configuration/configuration/#relabel_config)来“删除”其中的某些指标。
一段时间以来,我们一直在努力解决一个问题,即Prometheus会消耗越来越多的内存,直到最终由于内存不足错误(OOM)使容器崩溃。即使在应用程序上投入了巨大的内存容量之后,这种情况似乎仍会发生。更糟糕的是,当它确实崩溃时,启动prometheus需要重放 write-ahead-log ,这会花费好几个小时才能使prometheus再次正常。
最终,我们追踪到这些OOM的来源是Grafana与Prometheus之间的交互,其中Grafana在Prometheus上使用API(
/api/v1/series)并查询{le!=""}。对于有大量结果的查询,/api/v1/series在时间和空间上都是不受限制的,但这将消耗越来越多的内存和时间。即使在请求者放弃并关闭连接后,它也继续增长。对于我们而言,内存不足,Prometheus最终会崩溃。我们提交了patch(https://github.com/openai/prometheus/pull/1)Prometheus,将这个API包含在一个上下文中,以强制超时,从而完全修复这个bug。虽然Prometheus崩溃的频率比较小,但在确实需要重新启动它的时候,WAL replay仍然是一个问题。在Prometheus收集新指标和为查询提供服务之前,通常需要花费几个小时来重放所有WAL日志。在Robust Perception的帮助下,我们发现配置
GOMAXPROCS=24后会对prometheus有很大的改进。另外,Prometheus会在WAL replay期间尝试使用所有内核,而对于有很多内核的服务器,争用会破坏其性能。我们正在尝试新的配置选项来增加我们的监控能力,如下面“未解决的问题”部分所述。
健康检查
对于当前我们的这么大的集群,我们当然要依靠自动化来检测并自动从集群中删除行为异常的节点。我们当前已经建立了一些健康检查系统。
被动健康检查
一些健康检查是被动的,并且始终在所有节点上运行。它们监控基本的系统资源,例如网络可达性,磁盘损坏或磁盘容量或GPU错误。GPU会以多种不同方式出现问题,但一个常见的问题是“Uncorrectable ECC error.”。英伟达的数据中心GPU管理器(DCGM)可以很容易地查询这个错误以及其他的一些“Xid”错误。我们跟踪这些错误的一种方法是通过dcgm-exporter(https://github.com/NVIDIA/gpu-monitoring-tools#dcgm-exporter)将指标抓取到我们的监控系统Prometheus中。该指标为
DCGM_FI_DEV_XID_ERRORS,表示最近发生的错误代码。此外,NVML设备查询API公开了有关GPU的运行状况的详细信息。一旦我们检测到错误,通常可以通过重置GPU或系统来修复它们,尽管在某些情况下,它确实需要从底层上进行物理替换GPU。
健康检查的另一种形式是跟踪来自上游云供应商的维护事件。每个云供应商都提供了一种方式来知道当前的虚拟机是否应该为即将到来的维护事件停服,因为维护事件最终会导致中断。VM可能需要重新启动,这样可以应用底层hypervisor补丁,或者将物理节点更换其他硬件。
这些被动健康检查在所有节点的后台持续运行。如果健康检查一开始就失败,节点将自动被停用,因此不会在该节点上调度新的pod。对于更严重的健康检查失败,我们还将尝试逐出容器,以让所有当前节点运行的容器立即退出。这些仍由Pod本身决定,可以通过Pod Disruption Budget进行配置,以决定是否要让这种配置生效。最终,在所有Pod终止后或7天后(SLA),我们将强制终止VM。
主动GPU测试
不幸的是,并非所有的GPU问题都可以通过DCGM获知对应的错误代码。我们已经建立了自己的测试库,这些测试使用gpu来捕获额外的问题,并确保硬件和驱动程序按预期运行。这些测试不能在后台运行—它们需要独占使用GPU几秒钟或几分钟才能运行。
首先节点在初始上线时被称为“预检”系统,我们将在这些节点上运行这些测试。一开始,所有节点均以“预检”污点和标签加入群集。此污点会阻止在节点上调度常规Pod。将DaemonSet配置为在带有此标签的所有节点上运行预检测试pod。成功完成测试后,测试本身将去除污点和标签,然后该节点即可用于常规用途。
然后,我们还将在节点的生命期内定期运行这些测试。我们将其作为CronJob运行,使其可以在群集中的所有可用节点上运行。诚然,这是随机的,无法控制要测试的节点,但是我们发现,随着时间的流逝,它可以提供足够的覆盖范围,并且中断以及影响最少。
配额和资源使用
当我们扩大集群规模时,研究人员开始发现自己很难获得分配给他们的所有容量。传统的作业调度系统有很多不同的特性,可以在团队之间公平地运行工作任务,而Kubernetes没有这些特性。随着时间的推移,我们从那些作业调度系统中获得了灵感,并以Kubernetes原生的方式构建了一些功能。
Team taints
我们在每个集群中都有一个服务,即“ team-resource-manager”,它有多种功能。它的数据源是ConfigMap,它为在给定集群中所有研究团队指定了一些元组标签(节点选择器,要应用的团队标签,分配数量)。它将与集群中的当前节点进行协调,并使用
openai.com/team=teamname:NoSchedule标签来保留适当数量的节点 。“team-resource-manager”还有一个准入webhook服务,以便在提交每个作业时,根据提交者的团队成员资格应用相应的容忍度。使用污点可以使我们灵活地约束Kubernetes Pod调度程序,例如允许对优先级较低的Pod允许“any”容忍,这使得团队可以借用彼此的能力,而不需要重量级的协调。
CPU和GPU balloons
除了使用cluster autoscaler动态扩展我们的VM支持的集群之外,我们还使用它来修正(删除和重新添加)集群中不健康的成员。为此,我们将集群的“最小大小”设置为零,将集群的“最大大小”设置为可用容量。但是,如果集群autoscaler看到空闲节点,它将尝试缩小到需要的容量。由于多种原因(VM启动延迟、预先分配的成本、上面提到的API服务器影响),这种空闲扩展并不理想。
因此,我们为我们的CPU和GPU主机引入了一个balloon式部署。此部署包含一个有“最大大小”低优先级pod数的ReplicaSet。这些pod占用节点内的资源,因此autoscaler不认为它们是空闲的。但是,由于它们的优先级较低,调度程序可以立即将它们逐出,以便为实际工作腾出空间。(我们选择使用deployment而不是DaemonSet,以避免DaemonSet被视为节点上的空闲工作负载。)
需要注意的一件事是,我们使用容器抗亲和力来确保容器在节点上均匀分布。早期版本的Kubernetes调度程序有一个O(N^2)pod抗亲和力的性能问题。自Kubernetes 1.18起已修复此问题。
调度争用
我们的实验通常涉及一个或多个StatefulSet,每个StatefulSet都负责工作的不同部分。对于优化器,研究人员需要安排StatefulSet的所有成员,然后才能进行培训(因为我们经常使用MPI在成员之间进行协调,并且MPI对组成员身份更改很敏感)。
但是,默认情况下,Kubernetes不一定会优先满足来自一个StatefulSet的所有请求。例如,如果两个实验都请求集群100%的容量,那么Kubernetes可能只调度每个实验的一半pod,而不是调度一个或另一个实验的全部容量,从而导致死锁,最终导致两个实验都无法进行。
我们尝试了一些自定义调度程序的方式,但是遇到了一些极端情况,这些情况导致与常规Pod的调度方式发生冲突。Kubernetes 1.18引入了用于核心Kubernetes调度程序的插件架构,这使得在本地添加此类功能变得更加容易。我们最近将Coscheduling插件(https://github.com/kubernetes/enhancements/pull/1463)作为解决此问题的好方法。
未解决的问题
在扩展Kubernetes集群时,我们仍有很多问题需要解决。其中包括:
监控指标
以我们的规模,我们有很多问题都是与Prometheus的内置TSDB存储引擎相关,因为它的压缩很缓慢,一旦需要重启,就需要很长的时间来重放WAL(Write-Ahead-Log)。查询还会导致“query processing would load too many samples”错误。当前,我们正在迁移到另一个与Prometheus兼容的存储和查询引擎。
Pod网络traffic shaping
当我们扩展群集时,每个Pod都会被计算为有一定的Internet带宽。每个人对Internet带宽的总需求已经变得相当可观,并且我们的研究人员现在能够无意间对Internet出口(例如,下载数据和安装软件包)带来巨大的资源压力。
结论
我们发现Kubernetes对于我们的研究需求来说是一个非常灵活的平台。它有能力扩展以满足我们所需要的最苛刻的工作负载。尽管还有很多地方需要改进,OpenAI的超算团队将继续探索Kubernetes。
新钛云服 祝祥翻译
原文:
云和安全管理服务专家


