
-
Kubernetes中的优雅关闭和零停机时间部署

在Kubernetes中,创建和删除Pod是最常见的任务之一。当你执行滚动更新、扩展部署、发布新版本、执行作业和定时作业等操作时,都会创建Pod。但是,在Pod被驱逐后,例如将节点标记为不可调度时,Pod也会被删除并重新创建。如果这些Pod的性质是如此短暂,那么当一个Pod正在响应请求时,如果被告知关闭,会发生什么?在关闭之前,请求是否会完成?那么后续的请求呢?是否会被重定向到其他地方?在讨论Pod被删除时会发生什么之前,有必要谈谈当Pod被创建时会发生什么。假设你想在集群中创建以下Pod:pod.yaml apiVersion: v1kind: Podmetadata:name: my-podspec:containers:- name: webimage: nginxports:- name: webcontainerPort: 80你可以使用以下命令将YAML定义提交到集群中: $ kubectl apply -f pod.yaml一旦你输入该命令,kubectl会将Pod定义提交给Kubernetes API。 在数据库中保存集群的状态
Pod的定义被API接收并进行检查,随后存储在数据库(etcd)中。Pod也被添加到调度器的队列中。调度器执行以下操作: - 检查Pod的定义。
- 收集关于工作负载的详细信息,例如CPU和内存请求。
- 通过筛选器和判定的过程决定最适合运行该Pod的节点。
在此过程结束时:
- Pod在etcd中被标记为已调度。
- Pod被分配给一个节点。
- Pod的状态被存储在etcd中。
然而,此时Pod仍然不存在。
1. 当你使用
kubectl apply -f命令提交一个Pod的YAML文件时,该YAML文件会被发送到Kubernetes API。
2. API将Pod保存在数据库(etcd)中。
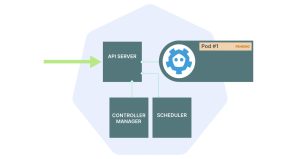
3. 调度器为该Pod分配了最适合的节点,Pod的状态变为Pending。此时,Pod只存在于etcd中。
在控制平面中发生了前述任务,并且状态存储在数据库中。
**那么是谁在你的节点上创建Pod呢?
Kubelet-Kubernetes代理
Kubelet 的任务是轮询控制平面以获取更新。 你可以想象kubelet不断地向主节点发出请求:“我负责管理工作节点1,是否有新的Pod需要我处理?” 当有一个Pod需要处理时,kubelet会创建它,在某种程度上是这样的。 kubelet并不是直接创建Pod。相反,它将工作委托给其他三个组件: -
容器运行时接口(CRI):负责为Pod创建容器。 -
容器网络接口(CNI):负责将容器连接到集群网络并分配IP地址。 -
容器存储接口(CSI):负责在容器中挂载卷。
在大多数情况下,容器运行时接口(CRI)的工作类似于: $ docker run -d <my-container-image>容器网络接口(CNI)更有趣,因为它负责以下任务: -
为Pod生成有效的IP地址。 -
将容器连接到网络的其他部分。
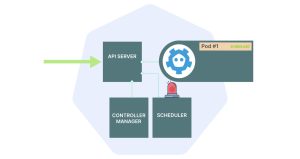
正如你所想象的,连接容器到网络并分配有效的IP地址有多种方式(可以选择IPv4或IPv6,甚至可以分配多个IP地址)。 以Docker为例,它会创建虚拟以太网对并将其附加到一个桥接器上;而AWS-CNI会直接将Pod连接到虚拟私有云(VPC)的其余部分。 当容器网络接口完成其工作时,Pod将连接到网络的其余部分,并被分配一个有效的IP地址。 但是存在一个问题。 kubelet知道IP地址(因为它调用了容器网络接口),但控制平面不知道。 没有人告诉主节点Pod已被分配了IP地址,并且准备好接收流量。在控制平面的视角中,Pod仍在创建中。 kubelet的工作是收集Pod的所有细节,例如IP地址,并将其报告给控制平面。 你可以想象,检查etcd将不仅揭示Pod的运行位置,还会显示其IP地址。 1. Kubelet定期向控制平面轮询更新。 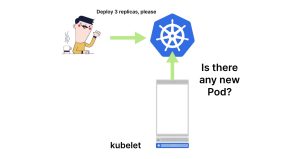
2. 当一个新的Pod被分配给它所在的节点时,kubelet会获取该Pod的详细信息。 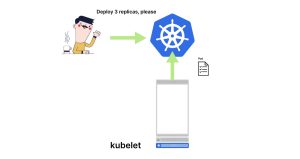
3. kubelet本身不会创建Pod,它依赖于三个组件:容器运行时接口(Container Runtime Interface)、容器网络接口(Container Network Interface)和容器存储接口(Container Storage Interface)。 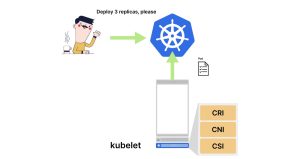
4. 一旦这三个组件都成功完成,Pod就会在你的节点上运行,并分配了一个IP地址。 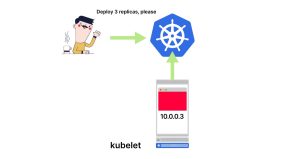
5. kubelet将IP地址报告给控制平面。 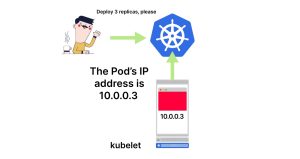
如果Pod不是任何服务的一部分,这就是任务的结束。Pod已创建并准备好使用。 当Pod是服务的一部分时,还需要进行一些额外的步骤。 Pods和服务
创建服务时,通常需要注意两个关键信息: -
选择器(selector):用于指定接收流量的Pod。 -
目标端口(targetPort):Pod用于接收流量的端口。
一个典型的服务的YAML定义如下: service.yaml apiVersion: v1kind: Servicemetadata:name: my-servicespec:ports:- port: 80targetPort: 3000selector:name: app当你使用kubectl apply将服务提交到集群时,Kubernetes会查找所有具有与选择器(name: app)相同标签的Pod,并收集它们的IP地址,但前提是它们通过了就绪探针(Readiness probe)。 然后,对于每个IP地址,Kubernetes会将IP地址和端口连接起来。 如果IP地址是10.0.0.3,目标端口是3000,Kubernetes会将这两个值连接起来,并称其为一个端点(endpoint)。 IP address + port = endpoint---------------------------------10.0.0.3 + 3000 = 10.0.0.3:3000这些端点将以另一个名为Endpoint的对象形式存储在etcd中。 有点困惑吗? 在Kubernetes中,以下术语适用: endpoint(本文和Learnk8s材料中以小写字母e表示)是IP地址和端口对的组合(10.0.0.3:3000)。 Endpoint(本文和Learnk8s材料中以大写字母E表示)是一组端点的集合。 Endpoint对象是Kubernetes中的一个真实对象,对于每个服务,Kubernetes会自动创建一个Endpoint对象。 你可以使用以下命令进行验证: $ kubectl get services,endpointsNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)service/my-service-1 ClusterIP 10.105.17.65 <none> 80/TCPservice/my-service-2 ClusterIP 10.96.0.1 <none> 443/TCPNAME ENDPOINTSendpoints/my-service-1 172.17.0.6:80,172.17.0.7:80endpoints/my-service-2 192.168.99.100:8443Endpoint会收集来自Pod的所有IP地址和端口。 但不仅如此。当发生以下情况时,Endpoint对象会使用新的端点列表进行刷新: -
创建一个Pod。 -
删除一个Pod。 -
在Pod上修改标签。
因此,你可以想象,每当你创建一个Pod,并且kubelet将其IP地址提交给主节点后,Kubernetes会更新所有的端点以反映这种变化: $ kubectl get services,endpointsNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)service/my-service-1 ClusterIP 10.105.17.65 <none> 80/TCPservice/my-service-2 ClusterIP 10.96.0.1 <none> 443/TCPNAME ENDPOINTSendpoints/my-service-1 172.17.0.6:80,172.17.0.7:80endpoints/my-service-2 192.168.99.100:8443很好,端点被存储在控制平面中,并且Endpoint对象已被更新。 1. 在这张图片中,你的集群中部署了一个单独的Pod。该Pod属于一个服务。如果你要检查etcd,你会发现Pod的详细信息以及服务的信息。 
2. 当部署新的Pod时会发生什么? 
3. Kubernetes需要跟踪Pod及其IP地址。服务应该将流量路由到新的端点,因此IP地址和端口应该被传播。 
4. 当另一个Pod被部署时会发生什么? 
5. 是的,完全相同的过程。在数据库中创建了新的“行”来表示新的Pod,并将端点进行传播。 
6. 当删除一个Pod时会发生什么? 
7. 服务立即移除该端点,最终该Pod也会从数据库中删除。 
8. Kubernetes对你的集群中的每一个小变化都做出反应。 
这里还有更多内容 你准备好开始使用你的Pod了吗? 在Kubernetes中使用端点
端点在Kubernetes中被多个组件使用。 Kube-proxy使用端点来在节点上设置iptables规则。 因此,每当端点(Endpoint对象)发生变化时,kube-proxy会获取新的IP地址和端口列表,并编写新的iptables规则。 -
让我们考虑一个由三个节点组成的集群,其中有两个Pod,并且没有服务。Pod的状态被存储在etcd中。
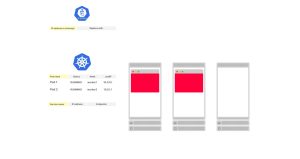
2. 当你创建一个服务(Service)时会发生什么? 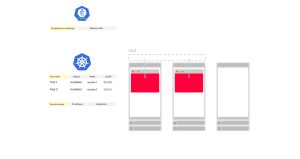
3. Kubernetes创建了一个Endpoint对象,并收集了来自Pod的所有端点(IP地址和端口对)。 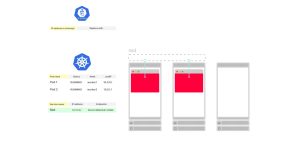
4. kube-proxy守护程序订阅对Endpoint的更改。 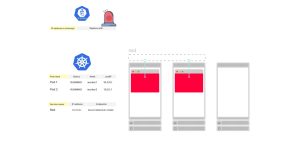
5. 当Endpoint被添加、删除或更新时,kube-proxy会获取新的端点列表。 
6. kube-proxy使用端点来在集群的每个节点上创建iptables规则。 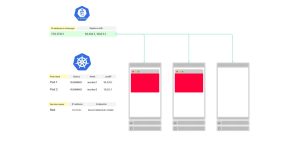
Ingress控制器也使用相同的端点列表。 Ingress控制器是集群中将外部流量路由到集群内的组件。 当你设置一个Ingress配置文件时,通常会指定Service作为目标: 入口.yaml apiVersion: networking.k8s.io/v1kind: Ingressmetadata:name: my-ingressspec:rules:- http:paths:- backend:service:name: my-serviceport:number: 80path: /pathType: Prefix实际上,流量并不会直接路由到Service。 相反,Ingress控制器建立了一个订阅,以便在Service的端点发生变化时收到通知。 Ingress直接将流量路由到Pods,跳过了Service。 正如你所想象的那样,每当Endpoint(对象)发生变化时,Ingress会获取新的IP地址和端口列表,并重新配置控制器以包括新的Pods。 -
在这张图片中,有一个带有两个副本的Ingress控制器和一个Service的部署(Deployment)。

2. 如果你想通过Ingress将外部流量路由到Pods,你应该创建一个Ingress配置文件(一个YAML文件)。

3. 一旦你运行 kubectl apply -f ingress.yaml命令,Ingress控制器就会从控制平面中获取配置文件。
4. Ingress的YAML文件中有一个 serviceName属性,用于描述应该使用哪个Service。
5. Ingress控制器从Service中检索端点列表,并跳过该Service。流量直接流向端点(Pods)。 
6. 当创建一个新的Pod时会发生什么? 
7. 你已经知道Kubernetes如何创建Pod并传播端点信息了。 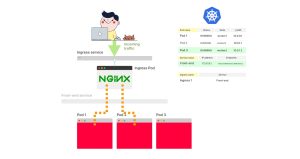
8. Ingress控制器订阅对端点的更改。由于有一个新的变化,它会获取新的端点列表。 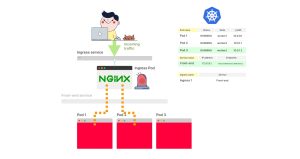
9. Ingress控制器将流量路由到新的Pod上。 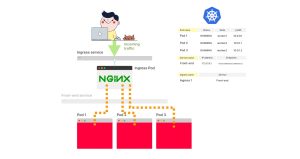
还有其他订阅端点更改的Kubernetes组件的示例。 集群中的DNS组件CoreDNS就是其中之一。 如果你使用Headless类型的Service,CoreDNS将需要订阅端点的更改,并在每次添加或删除端点时重新配置自身。 同样,服务网格(如Istio或Linkerd)、云服务提供商用于创建类型为LoadBalancer的服务,以及无数的操作员都会使用这些端点。 你必须记住,有多个组件订阅端点的更改,它们可能在不同的时间接收到关于端点更新的通知。 这就足够了,或者还有在创建Pod后发生的事情吗? 创建Pod时发生的主要步骤的简要回顾: -
Pod被存储在etcd中。 -
调度器分配一个节点,并将该节点写入etcd。 -
kubelet收到新的已调度Pod的通知。 -
kubelet将创建容器的任务委托给容器运行时接口(CRI)。 -
kubelet将容器连接到容器网络接口(CNI)的任务委托给它。 -
kubelet将容器中的挂载卷的任务委托给容器存储接口(CSI)。 -
容器网络接口分配一个IP地址。 -
kubelet将IP地址报告给控制平面。 -
IP地址被存储在etcd中。
如果你的Pod属于一个Service: -
kubelet等待成功的就绪探针(Readiness probe)。 -
所有相关的端点(对象)都会收到变更的通知。 -
端点将新的端点(IP地址+端口对)添加到它们的列表中。 -
Kube-proxy收到端点变更的通知。Kube-proxy在每个节点上更新iptables规则。 -
Ingress控制器收到端点变更的通知。控制器将流量路由到新的IP地址上。 -
CoreDNS收到端点变更的通知。如果Service的类型是Headless,DNS条目将被更新。 -
云服务提供商收到端点变更的通知。如果Service的类型是LoadBalancer,新的端点将作为负载均衡池的一部分进行配置。 -
集群中安装的任何服务网格都会收到端点变更的通知。 -
任何订阅端点变更的其他操作员也会收到通知。
对于一个看似普通的任务——创建一个Pod来说,这个列表确实很长。 Pod已经运行起来了。现在是时候讨论一下当你删除Pod时会发生什么了。 删除Pod
你可能已经猜到了,但是当删除Pod时,你需要按照相同的步骤但是逆序进行操作。 首先,应该从Endpoint(对象)中移除端点。 这次Readiness probe会被忽略,并且端点会立即从控制平面中删除。 这反过来会触发kube-proxy、Ingress控制器、DNS、服务网格等所有事件。 这些组件将更新其内部状态,并停止将流量路由到该IP地址。 由于这些组件可能正在执行其他操作,无法保证从其内部状态中删除IP地址需要多长时间。对于某些组件来说,可能只需要不到一秒的时间;而对于其他组件来说,可能需要更长的时间。 对一些来说,这可能只需要不到一秒钟;对其他来说,这可能需要更多。 1. 如果你使用 kubectl delete pod删除一个Pod,该命令首先会发送到Kubernetes API。
2. 该消息会被控制平面中的特定控制器——Endpoint控制器所拦截。 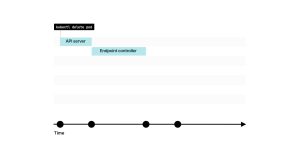
3. Endpoint控制器向API发送命令,将IP地址和端口从Endpoint对象中移除。 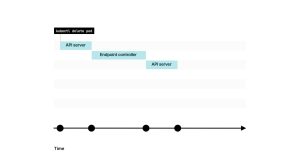
4. 谁会监听Endpoint的更改?kube-proxy、Ingress控制器、CoreDNS等组件会收到关于这一变更的通知。 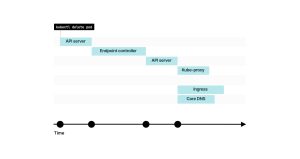
5. 一些组件,如kube-proxy,可能需要额外的时间来进一步传播这些更改。 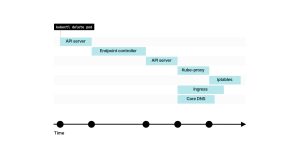
与此同时,etcd中的Pod状态被更改为Terminating(终止中)。 kubelet收到此变更的通知,并进行以下操作: -
将容器中的任何挂载卷从容器存储接口(CSI)卸载。 -
将容器从网络中分离,并释放IP地址给容器网络接口(CNI)。 -
将容器销毁给容器运行时接口(CRI)。
换句话说,Kubernetes按照与创建Pod完全相同的步骤来进行反向操作。 1. 如果你使用 kubectl delete pod删除一个Pod,该命令首先会发送到Kubernetes API。
2. 当kubelet轮询控制平面以获取更新时,它会注意到Pod已被删除。 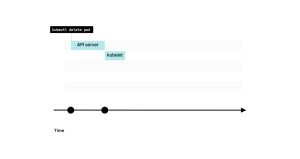
3. kubelet将销毁Pod的任务委托给容器运行时接口(Container Runtime Interface)、容器网络接口(Container Network Interface)和容器存储接口(Container Storage Interface)。 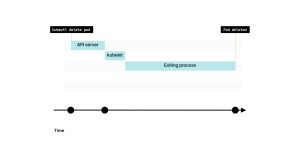
然而,这里存在一个微妙但关键的区别。 当你终止一个Pod时,移除端点和向kubelet发送的信号同时发出。 当你首次创建一个Pod时,Kubernetes会等待kubelet报告IP地址,然后开始端点传播。 然而,当你删除一个Pod时,事件会并行发生。 这可能导致多种竞争条件的出现。 如果在端点传播之前删除了Pod会怎样呢? 1. 删除端点和删除Pod同时进行。 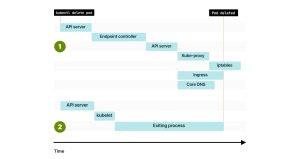
2. 因此,在kube-proxy更新iptables规则之前,你可能会先删除端点。 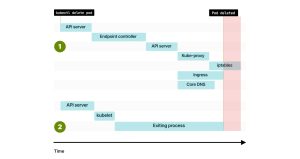
3. 或者你可能更幸运,只有在端点完全传播之后才删除Pod。 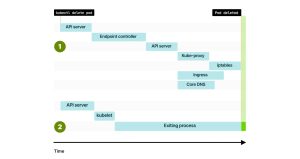
优雅关闭
当一个Pod在从kube-proxy或Ingress控制器中移除端点之前被终止时,你可能会遇到停机时间。 如果仔细思考一下,这是有道理的。 Kubernetes仍然将流量路由到该IP地址,但Pod已经不存在了。 Ingress控制器、kube-proxy、CoreDNS等组件没有足够的时间将IP地址从其内部状态中移除。 理想情况下,Kubernetes应该在删除Pod之前等待集群中的所有组件都具有更新的端点列表。 但是Kubernetes并不是这样工作的。 Kubernetes提供了强大的原始组件来分发端点(例如Endpoint对象和更高级的抽象,如Endpoint Slices)。 然而,Kubernetes并不验证订阅端点变更的组件是否与集群状态保持同步。 那么,为了避免这种竞争条件并确保在端点传播后删除Pod,你可以做些什么呢? 你应该等待。当Pod即将被删除时,它会收到一个SIGTERM信号。 你的应用程序可以捕获该信号并开始关闭。 由于在Kubernetes中不太可能立即从所有组件中删除端点,你可以: -
在退出之前等待更长的时间。 -
尽管收到SIGTERM信号,仍然处理传入的流量。 -
最后,关闭现有的长连接(例如数据库连接或WebSockets)。 -
关闭进程。
你应该等待多长时间呢?默认情况下,Kubernetes会发送SIGTERM信号,并在强制终止进程之前等待30秒钟。 因此,你可以在最初的15秒内继续正常运行。 希望这个时间间隔足够将端点移除的更改传播到kube-proxy、Ingress控制器、CoreDNS等组件。 随着时间的推移,越来越少的流量会到达你的Pod,直到最终停止。 在15秒之后,可以安全地关闭与数据库(或任何持久连接)的连接并终止进程。 如果你认为需要更多时间,可以在20或25秒时停止进程。 但是,请记住,Kubernetes将在30秒后强制终止进程(除非你在Pod定义中更改了terminationGracePeriodSeconds)。 如果无法更改代码以等待更长时间怎么办?你可以调用一个脚本等待固定的时间,然后让应用程序退出。 在调用SIGTERM之前,Kubernetes在Pod中提供了一个preStop钩子。你可以将preStop钩子设置为等待15秒钟。 让我们看一个示例: pod.yaml apiVersion: v1kind: Podmetadata:name: my-podspec:containers:- name: webimage: nginxports:- name: webcontainerPort: 80lifecycle:preStop:exec:command: ["sleep", "15"]preStop钩子是Pod生命周期钩子之一。 15秒的延迟是推荐的时间吗?这取决于情况,但这可能是开始测试的合理方式。 以下是你可以选择的选项的总结: 1. 你已经知道,当一个Pod被删除时,kubelet会收到这一变更的通知。 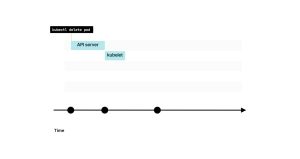
2. 如果Pod具有preStop钩子,它会首先被调用。 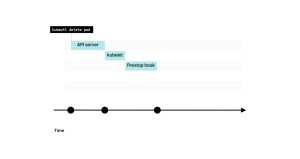
3. 当preStop钩子完成后,kubelet会向容器发送SIGTERM信号。从那时起,容器应该关闭所有长连接并准备终止。 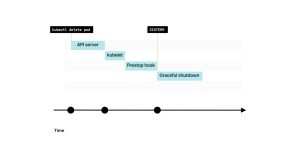
4. 默认情况下,进程有30秒的时间退出,其中包括preStop钩子的执行时间。如果进程在此期间未退出,kubelet将发送SIGKILL信号并强制终止进程。 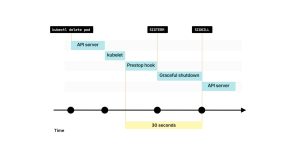
5. kubelet通知控制平面成功删除了该Pod。 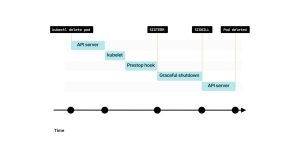
优雅期限和滚动更新
优雅关闭适用于被删除的Pod。 但如果你不删除Pod呢?即使你不删除Pod,Kubernetes也会定期删除Pod。 特别是,每当你部署应用程序的新版本时,Kubernetes会创建和删除Pod。 当你在部署中更改镜像时,Kubernetes会逐步推出变更。 pod.yaml apiVersion: apps/v1kind: Deploymentmetadata:name: appspec:replicas: 3selector:matchLabels:name: apptemplate:metadata:labels:name: appspec:containers:- name: app# image: nginx:1.18 OLDimage: nginx:1.19ports:- containerPort: 3000如果你有三个副本,并且在提交新的YAML资源给Kubernetes后,Kubernetes会: -
创建一个包含新容器镜像的Pod。 -
销毁一个现有的Pod。 -
等待Pod就绪。
然后它会重复上述步骤,直到所有的Pod都迁移到新版本。 Kubernetes只有在新的Pod准备好接收流量(也就是通过了就绪性检查)后才会重复每个周期。 Kubernetes在继续处理下一个Pod之前是否等待Pod被删除? 不会。 如果你有10个Pod,并且每个Pod需要2秒钟准备就绪和20秒钟关闭,情况如下: -
首先创建一个新的Pod,并终止一个之前的Pod。 -
新的Pod需要2秒钟准备就绪,然后Kubernetes创建一个新的Pod。 -
与此同时,正在终止的Pod保持终止状态20秒钟。
在20秒钟之后,所有新的Pod都处于活动状态(10个Pod,在2秒钟后准备就绪),而之前的10个Pod都处于终止状态(第一个终止的Pod即将退出)。 总体而言,在短时间内你将拥有两倍数量的Pod(10个运行中,10个终止中)。 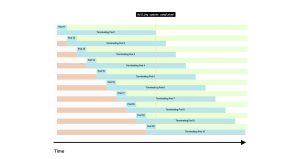
与就绪探针相比,宽限期限越长,你将同时拥有更多的运行中(以及终止中)的Pod。 这是一件坏事吗?不一定,因为你要小心地确保不丢失连接。 终止长时间运行的任务
那对于长时间运行的作业呢? 如果你正在转码一个大型视频,有没有办法延迟停止Pod的操作? 想象一下,你有一个包含三个副本的部署。 每个副本被分配了一个视频进行转码,并且这个任务可能需要几个小时才能完成。 当你触发滚动更新时,Pod在被终止之前有30秒的时间来完成任务。 你如何避免延迟关闭Pod的操作?你可以将terminationGracePeriodSeconds增加到几个小时。 然而,在那个时间点上,Pod的端点是无法访问的。 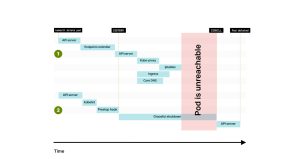
如果你将指标暴露用以监控Pod,你的监控工具将无法访问你的Pod。 为什么会这样? 像Prometheus这样的工具依赖于端点来抓取集群中的Pod。 然而,一旦你删除Pod,端点删除的信息会在集群中传播,甚至传递给Prometheus! 与其增加宽限期限,你应该考虑为每个新版本创建一个全新的部署。 当你创建一个全新的部署时,现有的部署将保持不变。 长时间运行的作业可以继续正常处理视频。一旦它们完成,你可以手动删除它们。 如果你希望自动删除它们,你可以设置一个自动缩放器,当任务用尽时,它可以将部署的副本数缩减为零。 这种 Pod 自动缩放器的一个例子是 Osiris——一个 Kubernetes 的通用、缩放到零的组件。 这种技术有时被称为Rainbow Deployments,在需要保持先前的Pod运行时间长于宽限期限的情况下非常有用。 另一个很好的例子是WebSockets。如果你正在向用户实时传输更新,你可能不希望每次发布时都终止WebSockets。 如果你在一天内频繁发布,这可能会导致实时数据流中断多次。 为每个发布创建一个新的部署是一个不太直观但更好的选择。 现有用户可以继续传输更新,而最新的部署为新用户提供服务。 随着用户从旧的Pod断开连接,你可以逐渐减少副本并淘汰过去的部署。 总结
你应该注意从集群中删除的Pod,因为它们的IP地址可能仍然被用于路由流量。 与立即关闭Pod不同,你应该考虑在应用程序中等待更长时间,或设置一个preStop钩子。 只有在集群中的所有端点都被传播并从kube-proxy、Ingress控制器、CoreDNS等中删除后,才应该删除Pod。 如果你的Pod运行长时间的任务,例如视频转码或使用WebSockets提供实时更新,请考虑使用Rainbow Deployments。在Rainbow Deployments中,你为每个发布创建一个新的部署,并在连接(或任务)耗尽时删除先前的部署。 你可以在长时间运行的任务完成后手动删除旧的部署。或者,你可以自动将部署的副本数缩减为零,以自动化该过程。 原文地址:https://learnk8s.io/graceful-shutdown
云和安全管理服务专家


