
-
Ceph Reef 测试:RGW 的Throughput 和ecRovery
01 介 绍
在阅读本文之前,我们推荐你先阅读⼀下之前的文章:《Putting Reef to the Test》,在这篇文章中,我们介绍了如何在不同的场景中测试上游 Reef,以根据 Quincy 基准来测试其功能和性能。
本文中的所有结果均由存储工作负载DFG团队提供。请继续阅读,了解我们如何通过填充RGW集群、 使其老化、诱发节点故障和启动恢复来测试Reef,从而收集最新的吞吐量和恢复结果。
02测试计划
以下测试旨在验证RADOS和RGW的功能,并测量大规模运行时的基线性能。所有测试均在上游版本的 Reef(18.1.2)上进行,并在上游版本的 Quincy(17.2.6)上重复进行,以便进行比较。测试采用了两 组对象大小:对象大小较小的工作负载使用5个 Warp驱动程序,每个桶一个固定大小(1KB、4KB、 8KB、64KB、256KB),而对象大小较大的工作负载则使用更通用的大小(1MB、4MB、8MB、 64MB、256MB)。
Test Cycle 1: RGWtest Workload
该测试周期填充了一个 RGW 群集,并测试了该群集刚开始运行时和老化几小时后的性能。此测试周期在 小型和通用大小的对象上进行。以下几点描述了测试周期的每个步骤:
- 群集填满-@4小时
- 对新群集进行1小时混合工作负载测试(45% 读取、35% 写入、15% 统计、5% 删除)
- 混合老化工作负载
3.1. 相同操作比率
3.2.小对象24小时,通用对象12小时 - 对老化群集进行1小时混合测试
Test Cycle 1: OSDfailure Workload
该测试周期填充了一个 RGW 集群,并测试了各种节点故障情况下的性能和恢复时间。本测试周期在小型和通用大小的对象上进行。以下各点描述了测试周期的每个步骤:
- 群集填满-@4小时
- 2小时混合工作负载 – 无故障
- 2小时混合工作负载 – 一个OSD节点(24 个 OSD)停止
- 2小时混合工作负载 – 另一个OSD节点(24 个 OSD)停止
- 2小时混合工作负载 – 缺少的OSD启动
- 监控恢复,直至所有PG都处于活动状态+已清理
03测试环境
以下几点说明了测试场景中使用的硬件、软件和工具。测试在两个集群上运行,每个集群有 8个OSD和4096个PG。我们在最新的Quincy上游版本(17.2.6)上运行每个测试场景,以收集基线数据,然后在Reef上游版本(18.2.1)上收集比较结果。结果使用minio warp工具生成和收集结果。
硬 件
- 3x MON / MGR nodes
- Dell R630
- 2x E5-2683 v3 (28 total cores, 56 threads) 128 GB RAM
- 8x OSD / RGW nodes
- Supermicro 6048R
- 2x Intel E5-2660 v4 (28 total cores, 56 threads)
- 256 GB RAM
- 192x OSDs (bluestore): 24 2TB HDD and 2x 800G NVMe for WAL/DB per node
- Pool: site{1,2}.rgw.buckets.data = EC 4+2, pgcnt=4096
- 五个节点,每个节点运行多个客户端
软 件
- RHEL9.2 (5.14.0-284.11.1.el9_2.x86_64)
- Quincy (17.2.6) 与 Reef (18.1.2) 进行比较
- 非默认设置
- log_to_file true
- mon_cluster_log_to_file true
- rgw_thread_pool_size 2048
- rgw_max_concurrent_requests 2048
- osd_memory_target 7877291758
- osd_memory_target_autotune false
- ceph balancer off
- PG autoscaler pg_num_min
- 4096 data
- 256 index
- 128 log/control/meta
使用的工具
- Warp v0.6.9-without-analyze
- RGWtest
- OSDfailure4
04 结 果
在集群填满和老化的情况下,我们看到 Reef 的吞吐量显著提高,尤其是对于小对象工作负载。在 OSD 出现故障的情况下,我们发现 Reef 的吞吐量在两种大小的对象上都有所下降;不过,这种下降在很大程 度上被更快的恢复时间所抵消,尤其是在小对象工作负载上。
RGWtest – 小对象大小调整
在此测试周期中执行的集群填充和老化工作负载显示,Reef 的吞吐量结果有了明显改善。下图显示了 Quincy(蓝色)和 Reef(红色)在集群刚启动时的读写吞吐量(MB/秒)对比。Reef 显示出明显的改善:
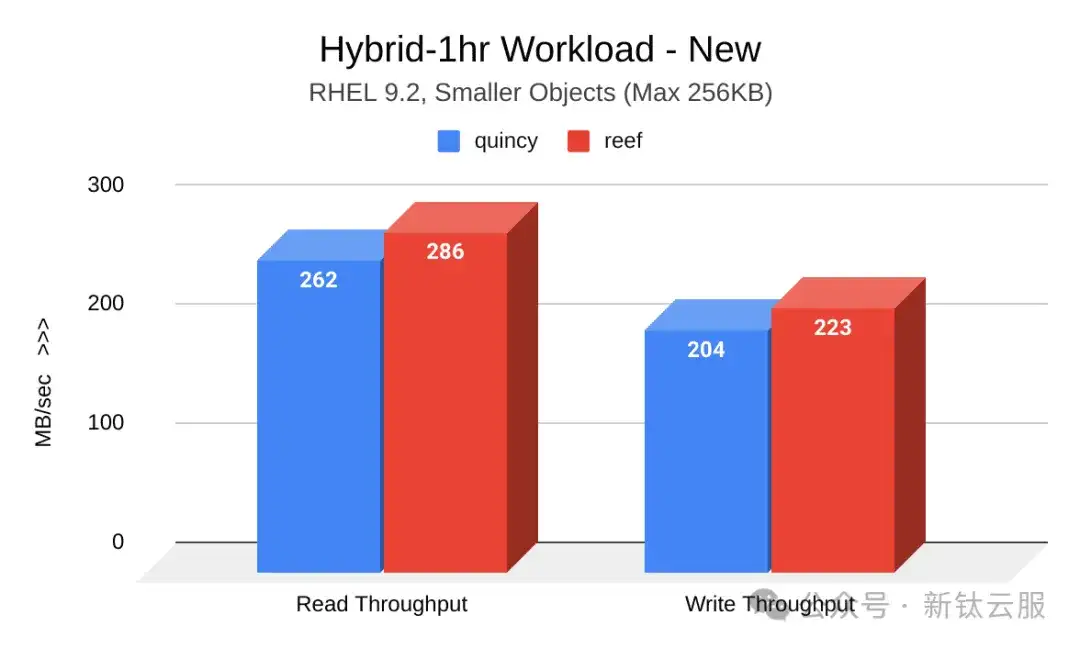
下图展示了集群老化后Quincy(蓝色)和Reef(红色)的读写吞吐量(MB/秒)对比。Quincy 显示出显着改善:
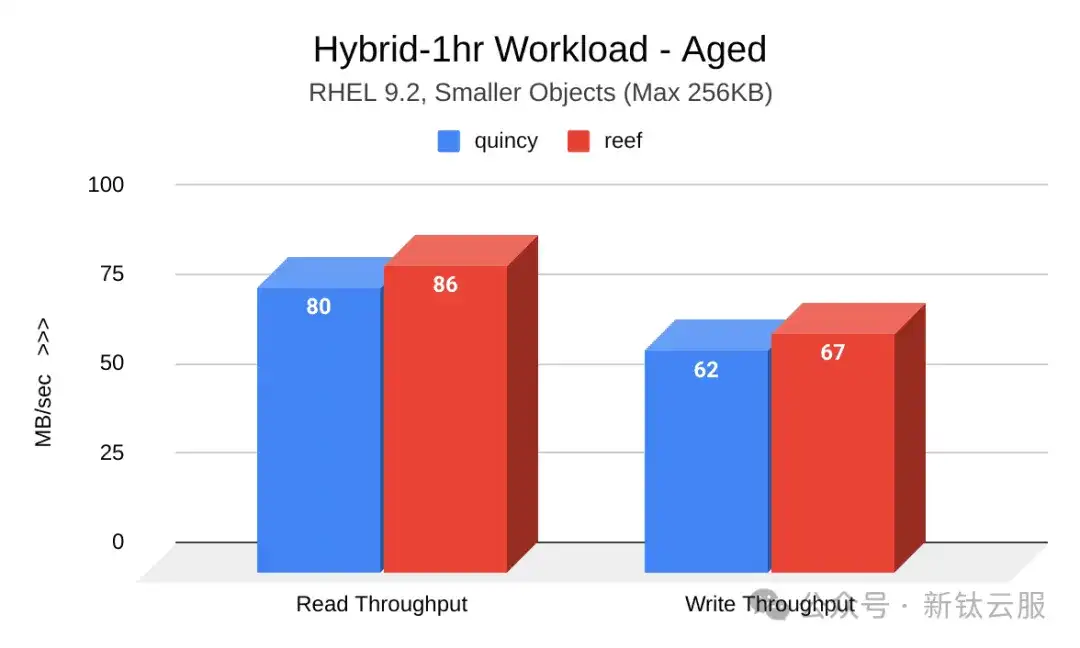
RGWtest – 小对象大小调整
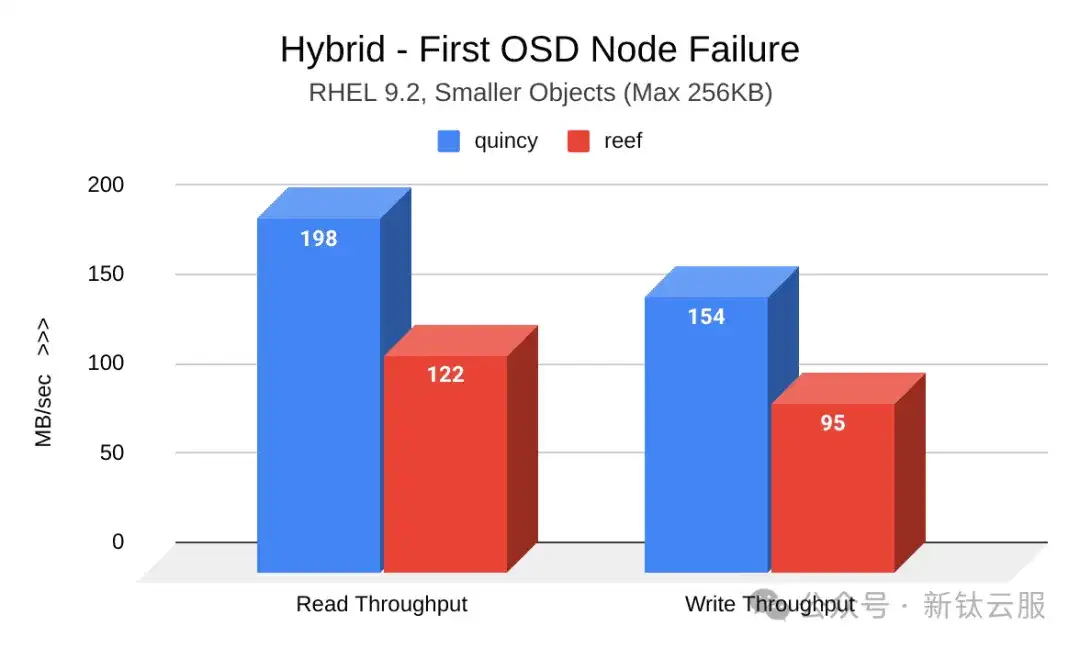
虽然诱发OSD节点故障的工作负载显示Reef 的吞吐量有所下降,但由于恢复时间大幅缩短,因此损失 也随之减少。
下图显示了第一次诱OSD节点故障后 Quincy(蓝色)和Reef(红色)之间读写吞吐量(MB/秒)的比较。Reef的吞吐量有所下降:
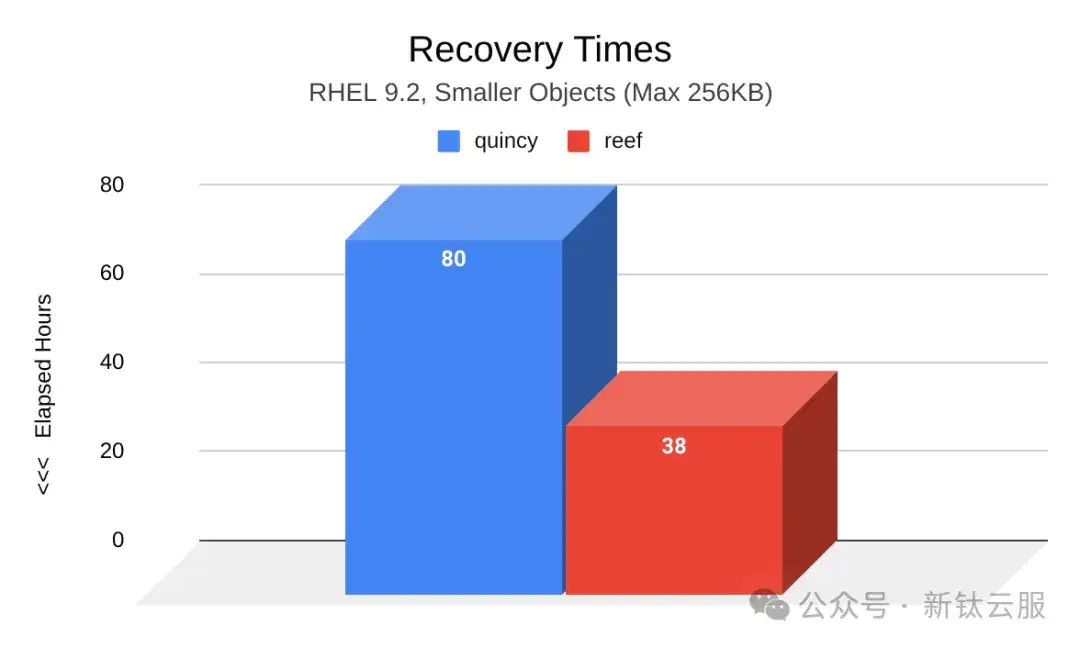
下图显示了Quincy(蓝色)和Reef(红色)额在两个OSD节点发生故障后的恢复时间(小时)对比。与Quincy相比,Reef中的PG达到active+clean状态所需的时间要短得多。Reef的恢复时间为38小时比Quincy的80小时少42小时。
RGWtest – 通用对象大小调整
在此测试周期中执行的集群填充和老化工作负载也表明,Reef 的吞吐量与 Quincy 的吞吐量相当,甚至略胜⼀筹。
下图显示了Quincy(蓝色)和Reef(红色)在新集群时的读写吞吐量(MB/秒)对比。Reef的结果与Quincy相当:
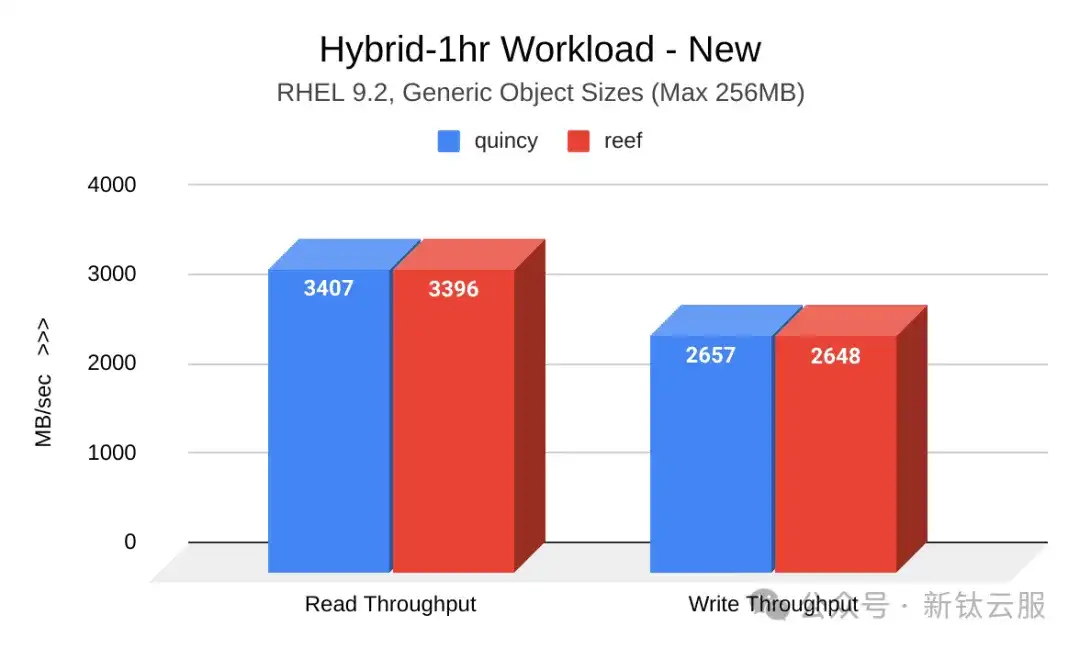
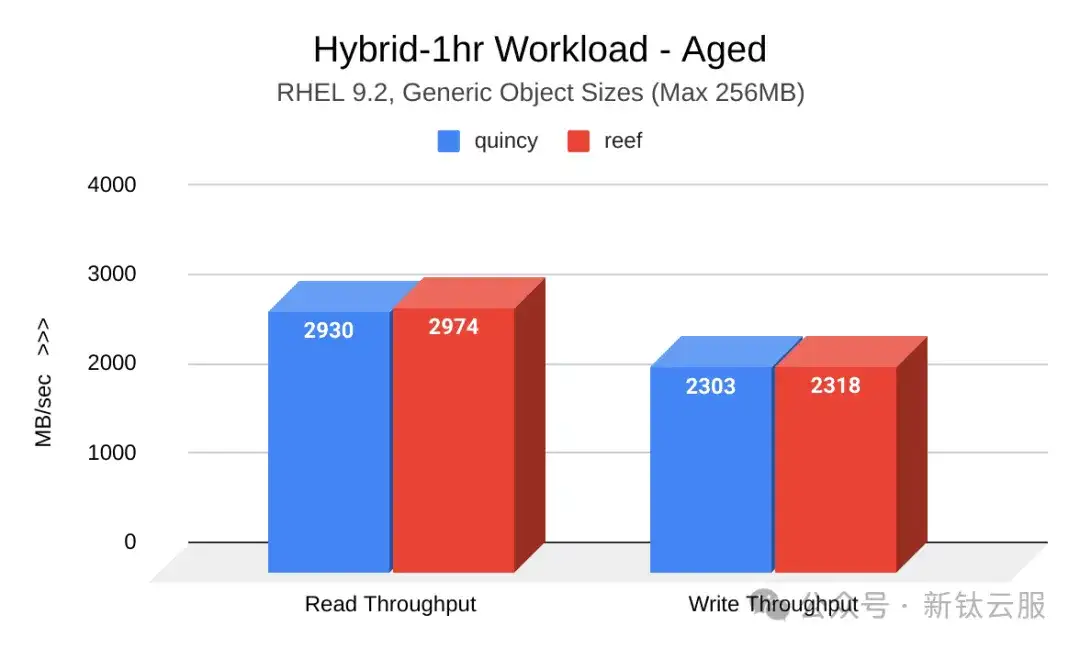
下图展示了集群老化后Quincy(蓝色)和Reef(红色)的读写吞吐量(MB/秒)对比。Reef 略有改善:
OSDfailure – 通用对象大小调整
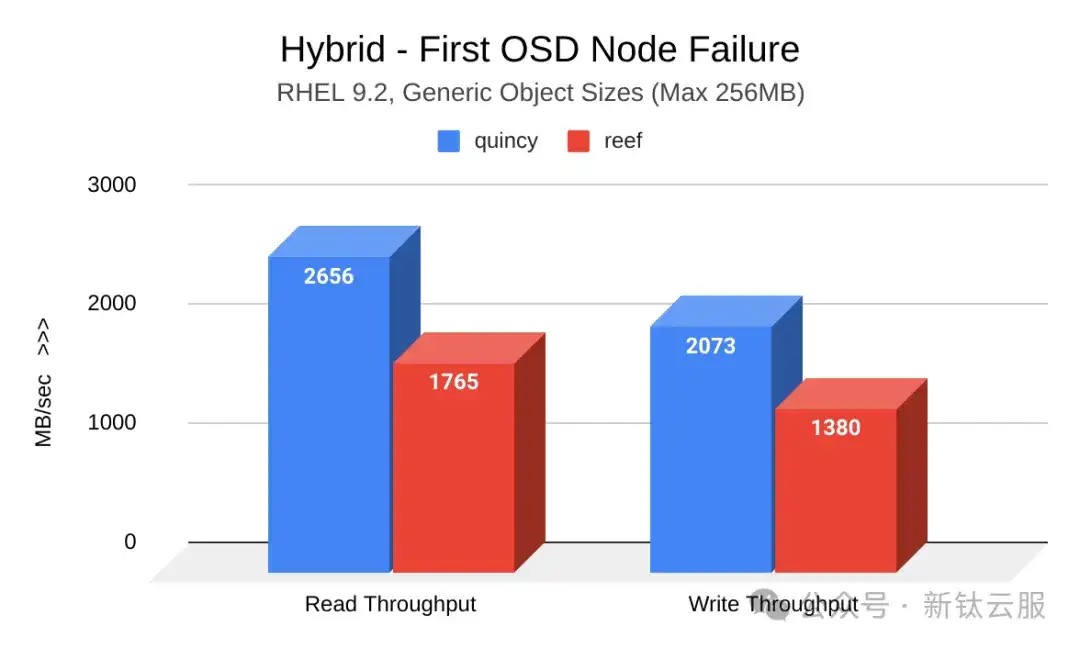
与小对象一样,通用对象 OSD 节点故障工作负载表明 Reef 吞吐量下降。然而,这种损失也伴随着恢复 时间的缩短。
下图显示了第一次引发OSD节点故障后Quincy(蓝色)和 Reef(红色)之间的读写吞吐量(MB/秒) 的比较。Reef显示吞吐量下降:
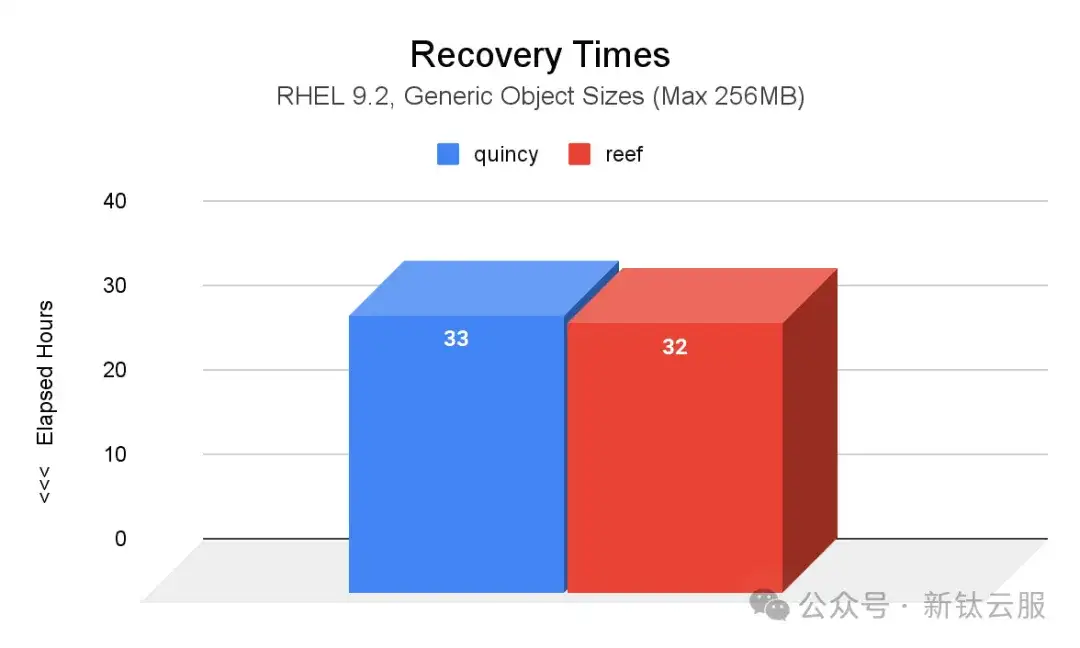
下图显示了两次引发的 OSD 节点故障后 Quincy(蓝色)和 Reef(红色)之间的恢复时间(小时)比较。与 Quincy 相比,Reef 中的 PG 达到 active+clean 状态所需的时间减少了1小时。
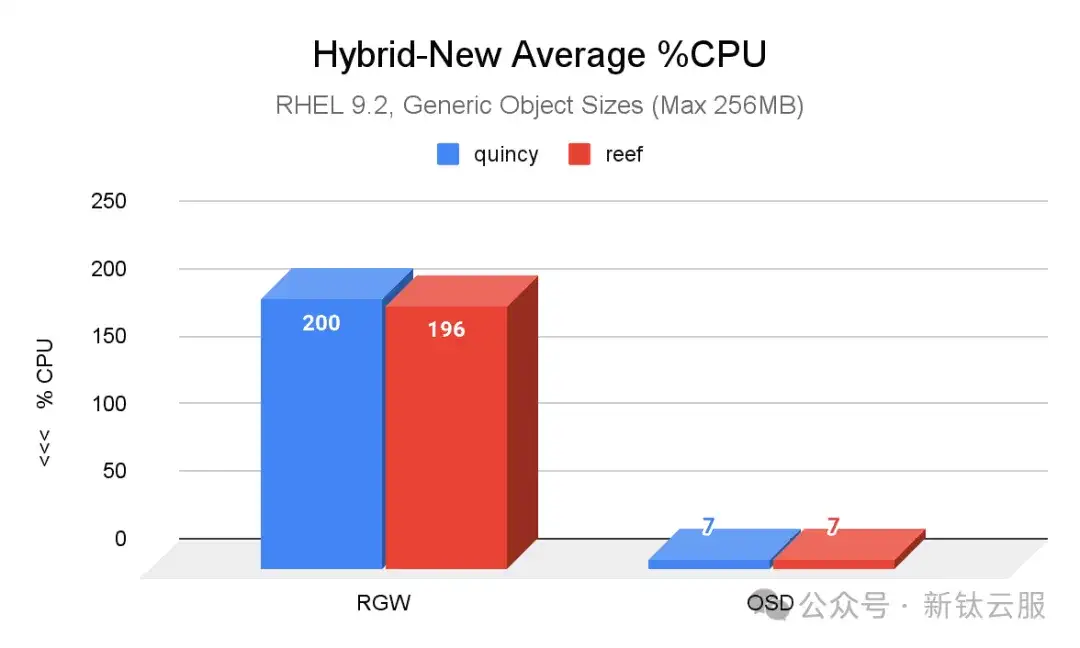
资源消耗
在集群填充和老化工作负载期间,以及在 OSD 故障情况下,也对 CPU 使用率进行了测试。事实证明, 这些结果在不同版本的小对象和一般对象中都具有可比性。
最明显的差异如下图所示,这是 Quincy(蓝色)和 Reef(红色)在新集群中使用通用对象大小时 CPU 平均使用百分比的比较。与 Quincy 相比,Reef 的 RGW CPU 占用率略有提高。
05 结 论
总体而言,在大多数情况下,升级到 Reef 意味着吞吐量的显著提高,特别是对于小对象工作负载。虽然在OSD故障情况下吞吐量可能会下降,但与Quincy相比,Reef的恢复时间要快得多,特别是对于小对 象工作负载。
随着越来越多的用户升级到 Reef,我们欢迎来自社区的所有性能反馈。
如有相关问题,请在文章后面给小编留言,小编安排作者第一时间和您联系,为您答疑解惑。
原文:https://ceph.io/en/news/blog/2023/putting-reef-to-the-test-throughput-and-recovery-in-rgw -workloads/
云和安全管理服务专家


