
-
Ceph 对象存储多站点复制:第二部分
系列回顾与目标
在本系列的第一部分中,我们介绍了Ceph对象存储的多站点特性,并准备好了用于部署和配置Ceph对象多站点异步复制的实验环境。
第二部分将详细讲解如何在两个Ceph集群之间建立初始的多站点复制配置,如下图所示:
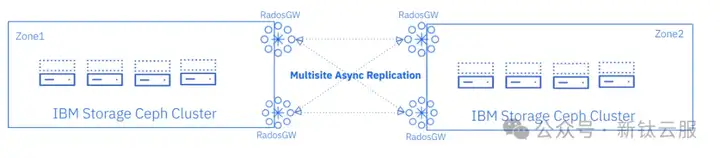
Ceph 对象存储多站点初始配置概述
自Quincy版本起,Ceph引入了一个名为rgw的新管理器模块,集成在cephadm编排器中。该模块简化了多站点复制的配置流程。本节将指导您如何使用rgw管理器模块,通过CLI在两个独立Ceph集群(每个集群作为一个区域)之间配置对象存储多站点复制。
创建RGW模块配置文件
我们首先为cluster1创建一个RGW模块配置文件。通过主机标签来定义哪些节点可以托管每个服务。对于复制RGW服务,我们设置rgwsync标签。任何配置了此标签的主机都将启动一个RGW服务,并使用文件中定义的规格。
[root@ceph-node-00 ~]# cat << EOF >> /root/rgw.spec placement: label: rgwsync count_per_host: 1 rgw_realm: multisite rgw_zone: zone1 rgw_zonegroup: multizg spec: rgw_frontend_port: 8000 EOF标记主机
我们的第一个集群中,我们希望在节点
ceph-node-00和ceph-node-01上运行rgwsync服务,因此我们需要标记相应的节点:[root@ceph-node-00 ~]# ceph orch host label add ceph-node-00.cephlab.com rgwsync Added label rgwsync to host ceph-node-00.cephlab.com [root@ceph-node-00 ~]# ceph orch host label add ceph-node-01.cephlab.com rgwsync Added label rgwsync to host ceph-node-01.cephlab.com启用RGW管理器模块并引导配置
标记节点后,我们启用RGW管理器模块并引导RGW多站点配置。引导多站点配置时,rgw管理器模块将执行以下步骤:
- 创建领域、区域组和区域,并应用周期
- 创建特定于区域名称的RGW RADOS池
- 创建RGW多站点复制同步用户
- 为每个RGW服务配置领域、区域组和区域
- 使用cephadm Orchestrator创建RGW服务
[root@ceph-node-00 ~]# ceph mgr module enable rgw [root@ceph-node-00 ~]# ceph rgw realm bootstrap -i rgw.spec Realm(s) created correctly. Please use 'ceph rgw realm tokens' to get the token.验证配置
我们可以通过以下命令检查领域、同步用户和RADOS池的创建情况:
[root@ceph-node-00 ~]# radosgw-admin realm list [root@ceph-node-00 ~]# radosgw-admin realm list { "default_info": "d85b6eef-2285-4072-8407-35e2ea7a17a2", "realms": [ "multisite" ] }多站点同步用户:
[root@ceph01 ~]# radosgw-admin user list | grep sysuser "Sysuser-multisite"Zone1 RGW RADOS 池:
[root@ceph01 ~]# ceph osd lspools | grep rgw 24 .rgw.root 25 zone1.rgw.log 26 zone1.rgw.control 27 zone1.rgw.meta一旦我们创建了第一个桶,桶索引池就会自动创建。此外,一旦我们将第一个对象/数据上传到
zone1中的存储桶,就会为我们创建数据池。默认情况下,副本为 3 的池是使用集群的预定义 CRUSH 规则replicated_rule创建的。如果我们想在数据池中使用纠删码 (EC) 或自定义故障域等,则需要在开始将数据上传到第一个存储桶之前,使用自定义内容手动预先创建池。[!CAUTION]
请务必仔细检查RGW池的Placement Groups(PG)数量是否正确,以确保所需的性能。我们可以选择为每个池启用带有批量标志(bulk flag)的PG自动扩展管理器模块,或者借助PG计算器(https://docs.ceph.com/en/squid/rados/operations/pgcalc/)预先静态计算池所需的PG数量。我们建议每个OSD的PG副本目标值为200,即”PG比例”。
[!CAUTION]
只有RGW数据池可以配置为使用纠删码(erasure coding)。RGW其他池必须配置为副本,默认复制因子为3(size=3)。RGW 服务已启动并正在端口 8000 上为 S3 端点提供服务:
[root@ceph-node-00 ~]# curl http://ceph-node-00:8000 <?xml version="1.0" encoding="UTF-8"?><ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Owner><ID>anonymous</ID><DisplayName></DisplayName></Owner><Buckets></Buckets></ListAllMyBucketsResult>RGW 管理器模块创建一个带有我们部署的编码信息的令牌。想要作为复制区域添加到我们的多站点配置的其他 Ceph 集群可以将此令牌导入到 RGW 管理器模块中,并使用单个命令配置和运行复制。
我们可以使用
ceph rgw realm tokens命令检查令牌的内容,并使用base64命令对其进行解码。正如您所看到的,它提供了辅助区域连接到主区域组并提取领域和区域组配置所需的信息。[root@ceph-node-00 ~]# TOKEN=$(ceph rgw realm tokens | jq .[0].token | sed 's/"//g') [root@ceph-node-00 ~]# echo $TOKEN | base64 -d { "realm_name": "multisite", "realm_id": "d85b6eef-2285-4072-8407-35e2ea7a17a2", "endpoint": "http://ceph-node-00.cephlab.com:8000", "access_key": "RUB7U4C6CCOMG3EM9QGF", "secret": "vg8XFPehb21Y8oUMB9RS0XXXXH2E1qIDIhZzpC" }从提示中可以看到,我们已经切换到第二个 Ceph 集群,从第一个集群复制了令牌,并与第一个集群类似地定义了其余参数。
[root@ceph-node-04 ~]# cat rgw2.spec placement: label: rgwsync count_per_host: 1 rgw_zone: zone2 rgw_realm_token: ewogICAgInJlYWxtX25hbWUiOiAibXVsdGlzaXRlIiwKICAgICJyZWFsbV9pZCI6ICIxNmM3OGJkMS0xOTIwLTRlMjMtOGM3Yi1lYmYxNWQ5ODI0NTgiLAogICAgImVuZHBvaW50IjogImh0dHA6Ly9jZXBoLW5vZGUtMDEuY2VwaGxhYi5jb206ODAwMCIsCiAgICAiYWNjZXNzX2tleSI6ICIwOFlXQ0NTNzEzUU9LN0pQQzFRUSIsCiAgICAic2VjcmV0IjogImZUZGlmTXpDUldaSXgwajI0ZEw4VGppRUFtOHpRdE01ZGNScXEyTjYiCn0= spec: rgw_frontend_port: 8000我们标记将运行 Ceph RGW 同步服务的主机:
[root@ceph-node-04 ~]# ceph orch host label add ceph-node-04.cephlab.com rgwsync Added label rgwsync to host ceph-node-04.cephlab.com [root@ceph-node-04 ~]# ceph orch host label add ceph-node-05.cephlab.com rgwsync Added label rgwsync to host ceph-node-05.cephlab.com启用该模块,并使用我们刚才创建的规范文件运行
ceph rgw zone create命令:[root@ceph02 ~]# ceph mgr module enable rgw [root@ceph02 ~]# ceph rgw zone create -i rgw2.spec --start-radosgw Zones zone2 created successfullyrgw管理器模块将负责使用多站点同步用户的访问密钥和密钥来拉取领域和区域组周期。最后,它将创建zone2并进行最后一次更新,以便所有区域都具有最新的配置更改,并将zone2添加到 zonegroupmultizg中。在radosgw-adminzonegroup get命令的以下输出中,我们可以看到区域组端点。我们还可以看到zone1是我们的 zonegroup 的主区域以及zone1和zone2的相应端点。[root@ceph-node-00 ~]# radosgw-admin zonegroup get { "id": "2761ad42-fd71-4170-87c6-74c20dd1e334", "name": "multizg", "api_name": "multizg", "is_master": true, "endpoints": [ "http://ceph-node-04.cephlab.com:8000", "http://ceph-node-05.cephlab.com:8000" ], "hostnames": [], "hostnames_s3website": [], "master_zone": "66df8c0a-c67d-4bd7-9975-bc02a549f13e", "zones": [ { "id": "66df8c0a-c67d-4bd7-9975-bc02a549f13e", "name": "zone1", "endpoints": [ "http://ceph-node-00.cephlab.com:8000", "http://ceph-node-01.cephlab.com:8000" ], "log_meta": false, "log_data": true, "bucket_index_max_shards": 11, "read_only": false, "tier_type": "", "sync_from_all": true, "sync_from": [], "redirect_zone": "", "supported_features": [ "compress-encrypted", "resharding" ] }, { "id": "7b9273a9-eb59-413d-a465-3029664c73d7", "name": "zone2", "endpoints": [ "http://ceph-node-04.cephlab.com:8000", "http://ceph-node-05.cephlab.com:8000" ], "log_meta": false, "log_data": true, "bucket_index_max_shards": 11, "read_only": false, "tier_type": "", "sync_from_all": true, "sync_from": [], "redirect_zone": "", "supported_features": [ "compress-encrypted", "resharding" ] } ], "placement_targets": [ { "name": "default-placement", "tags": [], "storage_classes": [ "STANDARD" ] } ], "default_placement": "default-placement", "realm_id": "beeea955-8341-41cc-a046-46de2d5ddeb9", "sync_policy": { "groups": [] }, "enabled_features": [ "resharding" ] }为了验证复制是否正常工作,我们创建一个用户和一个存储桶:
[root@ceph-node-00 ~]# radosgw-admin user create --uid='user1' --display-name='First User' --access-key='S3user1' --secret-key='S3user1key' [root@ceph-node-00 ~]# aws configure AWS Access Key ID [None]: S3user1 AWS Secret Access Key [None]: S3user1key Default region name [None]: multizg Default output format [None]: json [root@ceph-node-00 ~]# aws --endpoint http://s3.cephlab.com:80 s3 ls [root@ceph-node-00 ~]# aws --endpoint http://s3.cephlab.com:80 s3 mb s3://firstbucket make_bucket: firstbucket [root@ceph-node-00 ~]# aws --endpoint http://s3.cephlab.com:80 s3 cp /etc/hosts s3://firstbucket upload: ../etc/hosts to s3://firstbucket/hosts如果我们从第二个 Ceph 集群
zone2进行检查,我们可以看到所有元数据都已复制,并且我们在zone1中创建的所有用户和存储桶现在都存在于zone2中。[!CAUTION]
注意:在此示例中,我们将使用radosgw-admin命令进行检查,但我们也可以使用 S3 API 命令将 AWS 客户端指向第二个区域内 RGW 的 IP/主机名。[root@ceph-node-04 ~]# radosgw-admin user list [ "dashboard", "user1", "sysuser-multisite" ] [root@ceph-node-04 ~]# radosgw-admin bucket stats --bucket testbucket | jq .bucket "testbucket"要检查复制状态,我们可以使用
radosgw-admin sync status命令。例如:[root@ceph-node-00 ~]# radosgw-admin sync status realm beeea955-8341-41cc-a046-46de2d5ddeb9 (multisite) zonegroup 2761ad42-fd71-4170-87c6-74c20dd1e334 (multizg) zone 66df8c0a-c67d-4bd7-9975-bc02a549f13e (zone1) current time 2024-01-05T22:51:17Z zonegroup features enabled: resharding disabled: compress-encrypted metadata sync no sync (zone is master) data sync source: 7b9273a9-eb59-413d-a465-3029664c73d7 (zone2) syncing full sync: 0/128 shards incremental sync: 128/128 shards data is caught up with source总 结
回顾一下,在本系列的第二部分中,我们详细讲解了如何使用rgw管理器模块在两个站点/区域之间部署Ceph对象存储多站点复制。这只是一个开始,我们的目标是构建一个完整的部署,包括必要的负载均衡。

如有相关问题,请在文章后面给小编留言,小编安排作者第一时间和您联系,为您答疑解惑。
云和安全管理服务专家


