
-
阿里云函数计算对接kafka实战
 背景需求
背景需求阿里云函数计算式是按调用次数来计算费用的,无需服务器就能进行后端的一些处理,对于调用次数不是特别多的场景比较适用。可以节省成本,但是如果调用次数很多对服务器性能要求不是特别高的情况下建议还是用ECS来部署服务。
函数计算对接kafka实战
新建服务和函数
新建服务比较容易基本只要输入一个服务名称即可 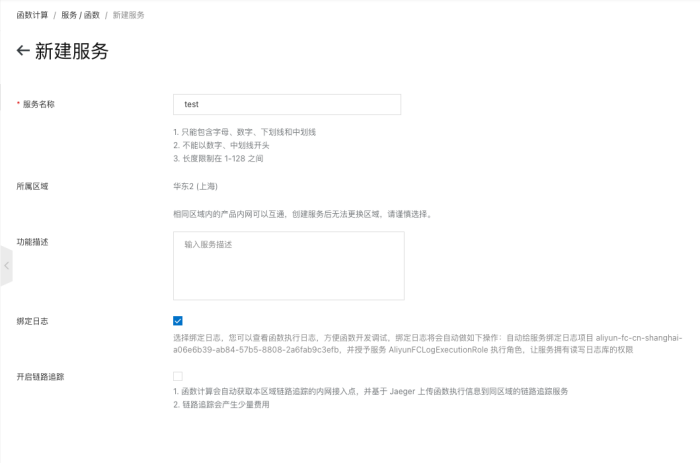
新建函数使用HTTP 函数,新手也可以尝试使用模版函数 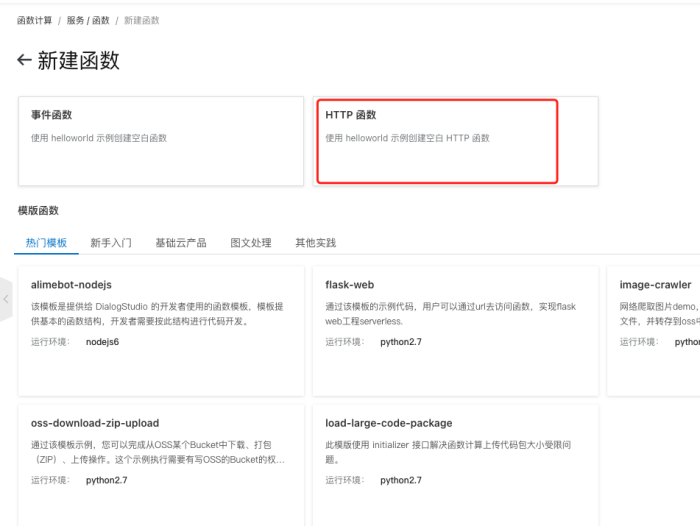
配置函数
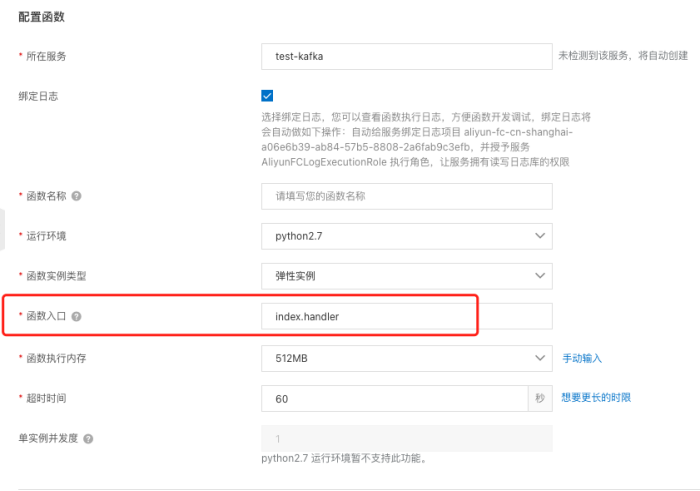
这里主要注意函数入口这个配置,Handler 的格式为 [文件名].[函数名]。例如创建函数时指定的 Handler 为 index.handler,那么文件名为 index.py,入口函数为 handler。 配置触发器
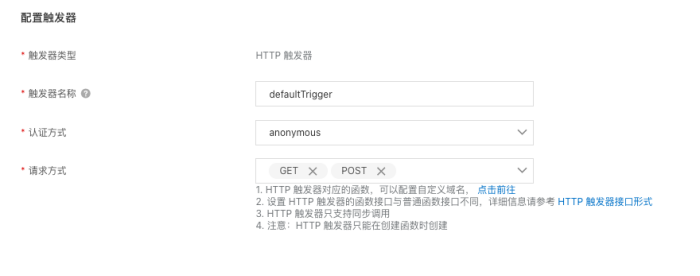
这里只是为了测试所以认证方式使用anonymous。 代码开发
首先要在代码根目录下安装python连接kafka的依赖包 pip install -t . kafka-python 然后开始编写setting.py这个是连接kafka的配置信息 vim setting.py kafka_setting = {
‘bootstrap_servers’: [“XXX”, “XXX”, “XXX”], #kafka连接地址
‘topic_name’: ‘XXX’, #使用的topic名称
‘consumer_id’: ‘XXX’ #使用的Consumer Group
}然后开始编写入口文件index.py # -*- coding: utf-8 -*-
# 导入连接kafka所需依赖包和配置
import socket
from kafka import KafkaProducer
from kafka.errors import KafkaErrorimport settingconf = setting.kafka_settingprint confHELLO_WORLD = b”Hello world!\n”def handler(environ, start_response):
context = environ[‘fc.context’]
request_uri = environ[‘fc.request_uri’]
for k, v in environ.items():
if k.startswith(“HTTP_”):
# process custom request headers
pass # get request_body
try:
request_body_size = int(environ.get(‘CONTENT_LENGTH’, 0))
except (ValueError):
request_body_size = 0
request_body = environ[‘wsgi.input’].read(request_body_size) # get request_method
request_method = environ[‘REQUEST_METHOD’] # get path info
path_info = environ[‘PATH_INFO’] # get server_protocol
server_protocol = environ[‘SERVER_PROTOCOL’] # get content_type
try:
content_type = environ[‘CONTENT_TYPE’]
except (KeyError):
content_type = ” ”# get query_string
try:
query_string = environ[‘QUERY_STRING’]
except (KeyError):
query_string = ” ”print ‘request_body: {}’.format(request_body)
print ‘method: {}\n path: {}\n query_string: {}\n server_protocol: {}\n’.format(request_method, path_info, query_string, server_protocol)
# do something herestatus = ‘200 OK’
response_headers = [(‘Content-type’, ‘text/plain’)]
start_response(status, response_headers)#以下是kafka操作部分,发送一个消息到kafka
producer = KafkaProducer(bootstrap_servers=conf[‘bootstrap_servers’],
api_version = (0,10),
retries=5)partitions = producer.partitions_for(conf[‘topic_name’])
print ‘Topic 下分区: %s’ % partitionstry:
future = producer.send(conf[‘topic_name’], ‘hello aliyun-kafka test!’)
future.get()
print ‘send message succeed.’
except KafkaError, e:
print ‘send message failed.’
print e
# return value must be iterable
return [HELLO_WORLD]备注:上面的函数脚本分别参考了阿里云的函数计算Hello World示例和python连接kafka示例,参考url如下: Hello World示例https://help.aliyun.com/document_detail/74756.html?spm=a2c4g.11186623.6.573.2be3dc876slGKm python连接kafka示例 https://code.aliyun.com/alikafka/aliware-kafka-demos/blob/master/kafka-python-demo/vpc/aliyun_kafka_producer.py Hello World示例必须要,因为这个是Http函数,需要加http请求参数和返回的状态码等信息。environ, start_response这两个参数是必选项。不加参数无法通过。具体信息可以查看帮助文档。 代码上传
通过文件夹和压缩包均可以上传代码 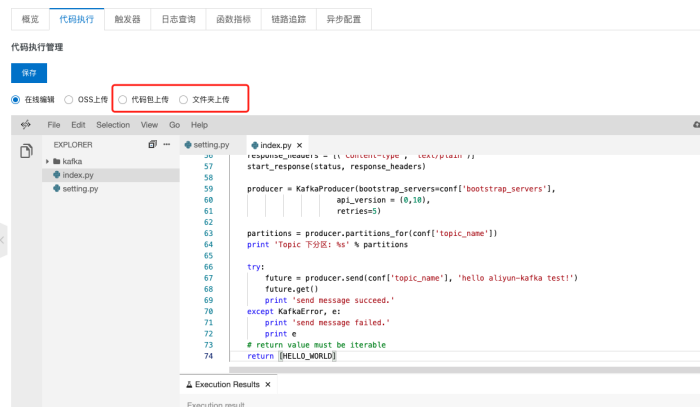
环境设置
配置服务允许访问VPC内资源 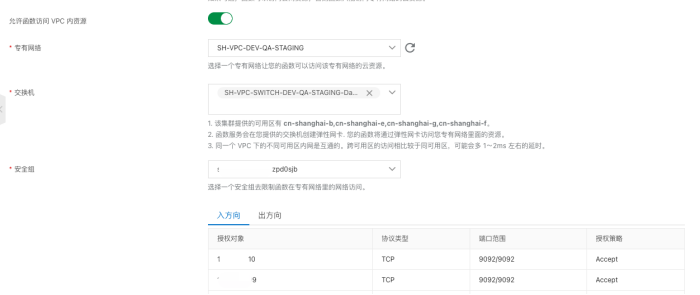
配置kafka所在安全组允许被函数计算内网地址访问 由于函数计算地址用的是域名,通过ping得到函数计算内网地址,然后用大段的子网覆盖它,避免ip变更导致无法访问 
配置函数计算访问kafka权限,这里给了管理权限,生产环境可以根据实际情况配自定义权限 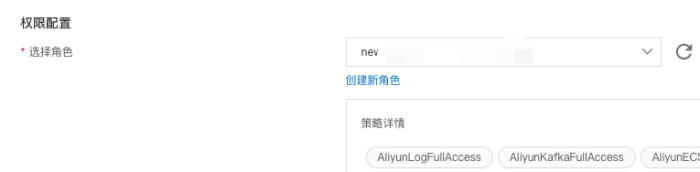
测试运行
直接点击代码执行下的执行按钮就能运行 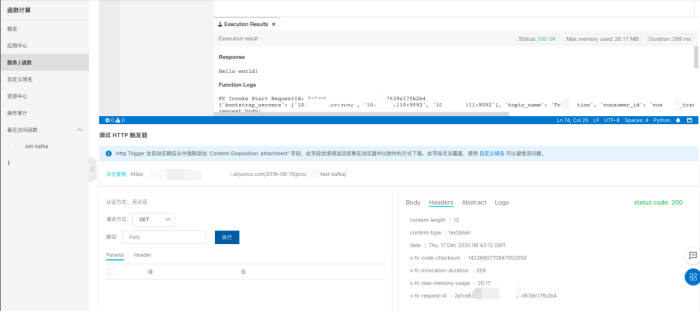
查看结果
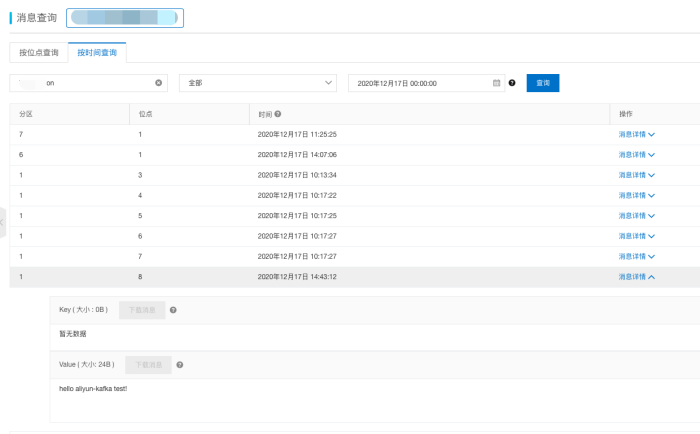
总结
函数计算对很多人来说还是一个新鲜的工具。未来也许会成为一种趋势。因为它不需要服务器,且在公司初期量不大的前提下能节省成本和运维维护的成本。 云管理服务专家 秦鸣原创
云和安全管理服务专家


