
-
如何有效追踪Kubernetes Application 流量!
一、文档说明
在我们的行业中,微服务的体系框架得到了很多人的支持和认可,也有越来越多的互联网公司采用微服务的形式运行服务,其中的利弊我这里也不再赘述。
对于微服务架构,监控和日志的观察显得格外的重要。在一个个微服务互相作用拼凑成的大网上,任何一个环节出现问题都可能是致命的问题。
分布式追踪与日志记录的相同点是保持服务健康和可预测的关键功能。与显示服务上发生了什么的日志相反,追踪允许开发人员和操作员追踪特定的请求以及它如何调用不同的服务和依赖关系。
它是围绕微服务体系结构设计的,与monolith体系结构不同,它使用许多小型服务来运行平台。这些服务相互通信,也与外部服务通信,以存储用户的请求信息。
那么本文就来介绍下Kubernetes分布式追踪解决方案。
二、Kubernetes分布式追踪解决方案
在monolith体系结构上使用微服务的好处:
-
易于维护:这是因为它简化了开发,测试和部署过程。 -
可扩展性更高:您可以增加或减少应用程序实例的数量,而不影响其他的系统或应用程序。
缺点是它会减少错误瓶颈检测的功能,这使得难以定位检测请求失败的原因。
分布式追踪通过监视请求和服务之间的数据交换的方式来简化检测,从而解决了这一问题。然后,收集有关请求失败或减慢的服务的信息并图形化展示出来。
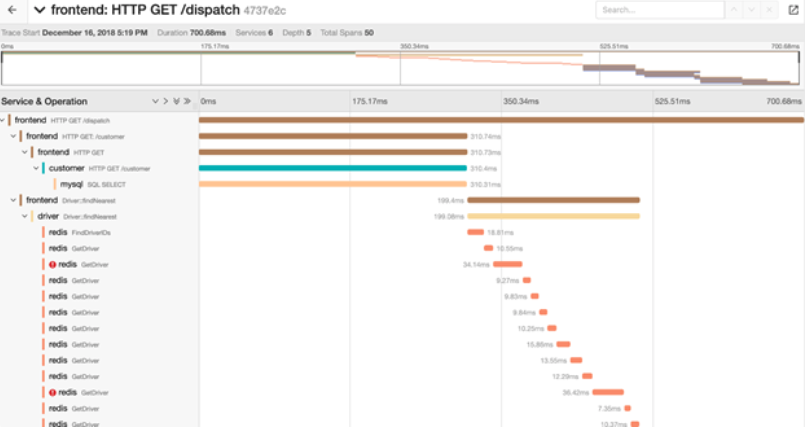
有一些工具可用于在Kubernetes中实现分布式追踪,每种工具提供不同的功能。在这里,我们介绍几个与Kubernetes一起使用的最受欢迎的分布式追踪平台:
-
比较完善的Zipkin -
Jaeger,这是基于Zipkin的更好的工具 -
Grafana Tempo,它与前两种工具的存储数据的方式完全不同 -
托管服务,AWS X-Ray
Jaeger
Jaeger是一种开源分布式追踪工具,最初由Uber开发。它旨在生产中运行,对性能的影响不大。它具有许多活动部件,可以提高吞吐量,但会使部署复杂化。
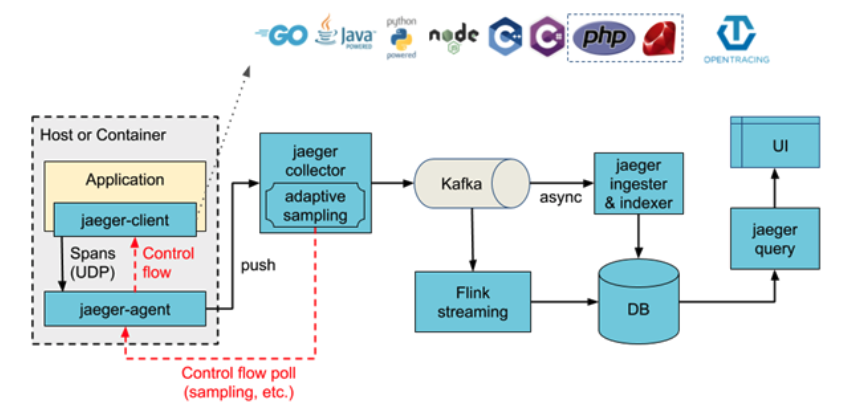
尽管对于其他平台也有一些非官方的库。这些客户端基于OpenTracing API,旨在生产中启用。但是追踪确实会带来计算成本,并且必须在以不影响整体性能的情况下对数据进行采样。
默认情况下,Jaeger客户端对0.1%的应用进行采样,并且可以通过Jaeger中央后端应用正确的采样策略,而无需为其每个服务进行特定配置。
Jaeger在其文档中有一整节专门介绍如何使用Kubernetes进行部署,因此部署简化版本并不难。并且必须在部署之前对其进行安装和配置,并提供三种部署策略:
-
AllInOne专为测试目的而设计。所有服务都部署到带有内存存储的单个Pod中。缺点是它不提供可伸缩性,也不可靠。 -
Production 允许具有多个副本和持久性存储,相对来说更可靠,适用于性能更高的分布式追踪应用程序。 -
Streaming 本质上是一种改进的生产策略,其中,将Kafka服务用于数据提取。这减轻了存储的压力,从而改善了查询和数据可视化带来的负载。
以上三种策略中的每一种都需要sidecar服务,该代理可以连接到仪表库并将追踪数据推送到收集器。每个部署都需要一个值为”sidecar.jaegertracing.io/inject”:”true”的注释,以指示Jaeger运维人员遵守该规则。
请注意,此功能仅可用于部署,而其他类型的Kubernetes组件(例如Pods和ReplicaSets)必须手动安装代理。
Zipkin
Zipkin最初受到Google Dapper的启发,最初是由Twitter开发的,现在是一个拥有专门社区的OSS组织。它具有与Jaeger相似的功能。
与Jager相比,Zipkin具有更简单的非分布式体系结构,可简化部署。但是,由于所有服务都构建在同一工件中,因此它的扩展性不如Jaeger。
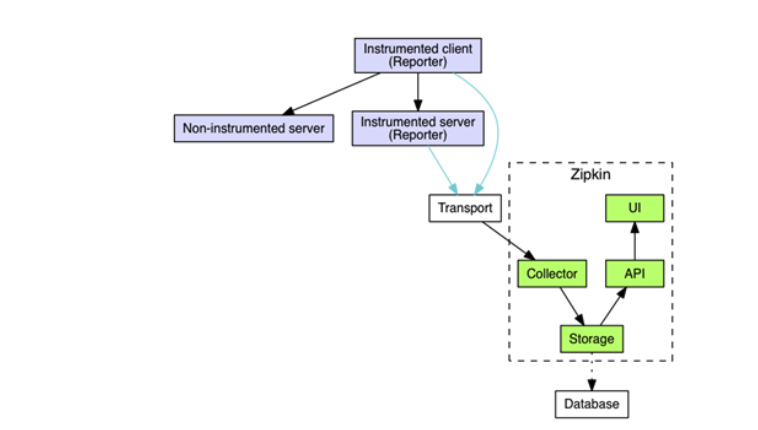
尽管Zipkin并未提供在Kubernetes上进行部署的方式(既不用于代理程序也不用于其服务),但它提供了Docker image,供您在环境中简单方便的运行。
该映像可以运行内存中的所有内容,也可以使用外部存储设备(例如Cassandra,MySQL或Elasticsearch)。但是,它不支持多个Zipkin实例,因此可伸缩性受到限制。
Grafana Tempo
Grafana Tempo于2020年发布,是一个新的竞争者,旨在解决其他分布式追踪工具的特定问题,特别是大型服务器的使用和数据采样的困难。
其他系统通过对追踪的数据建立索引来花费过多的资源,这会导致更高的成本并需要复杂的存储系统(例如,Cassandra或Elasticsearch)。尽管这些系统能够处理大量数据,但您需要支付更多费用才能部署大型集群。
另一方面,Grafana Tempo依赖于对象存储服务(例如Amazon S3),并使用其查询引擎来发现追踪信息,其他Grafana服务也使用该信息。
因此,尽管存储成本较便宜,但查询却很昂贵,这是因为消耗了更多时间并使用了更多CPU资源。请参见下面的图5中的Grafana Tempo体系结构。
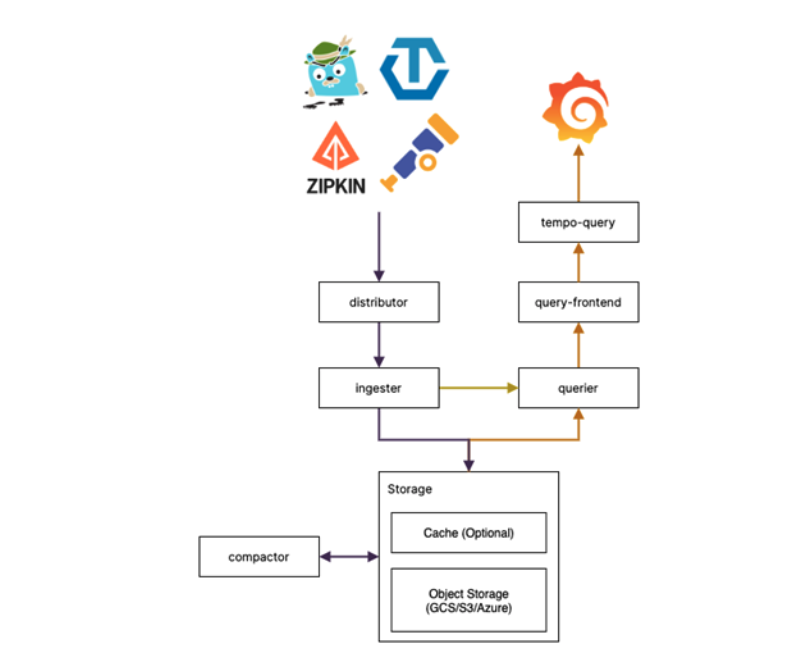
Tempo通过收集所有生成的数据来工作。这对于调试很有用,但是在捕获数据时可能会导致性能问题。通过使用Jaeger,您可以手动配置采样。
它没有为Kubernetes部署提供任何特殊功能。安装将需要在群集上部署以下服务。这些额外服务是否会增加部署成本或限制客户选择其他监视工具的灵活性?
-
Tempo backend -
Tempo-query engine -
Prometheus -
Grafana
至于存储,您所需要的只是在任何云平台上都可以轻松使用的基本对象存储。Tempo还侦听多个端口,每个协议侦听一个端口,以确保您使用可用的最佳工具库:

与Zipkin一样,没有代理或side-loaded服务可简化部署和配置。每个系统必须具有正确的配置,这增加了运营成本,并需要一个中央配置存储库。
AWS X-Ray
AWS X-Ray是一项托管服务,旨在为在AWS Cloud内运行的服务提供无缝的分布式追踪。作为特定于供应商的工具,它在外部服务方面的确实存在一些局限性。尽管如此,AWS团队甚至为自托管服务(例如MySQL或PostgreSQL)提供库和代理。
X-Ray提供了Go,Java,Node.js,Python,Ruby和.Net的库。像Jaeger一样,AWS X-Ray使用side-loaded代理来追踪数据连接并推送到后端。这样,您可以避免在运行时将大型配置属性放入应用程序中,并将所有数据提取工作分流到另一个服务。但是,在非托管环境中,它可能会增加更多的复杂性。
将X-Ray与Kubernetes结合使用非常简单,因为您无需部署任何其他后端服务或存储解决方案。该代理可以像Jaeger一样作为Kubernetes DaemonSet的方式来安装。
三、总结
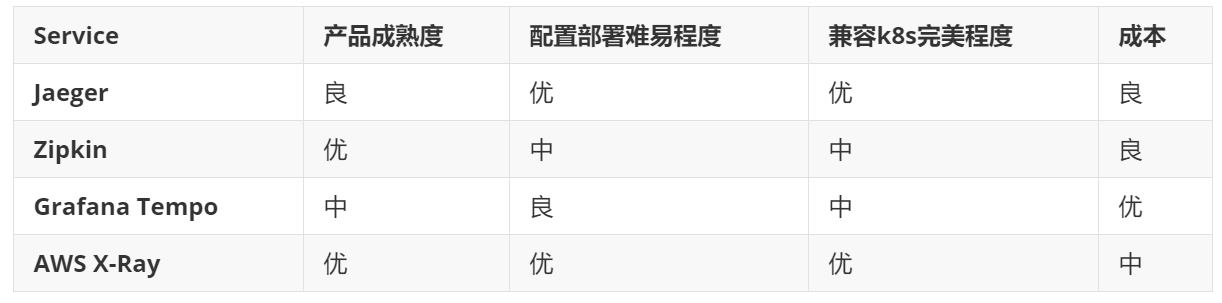 以此表来总结四个产品的竞争对比,优良中差来评级,当然,没有差的,毕竟都是行业主流的产品。业务级别的流量追踪,产品选型,需结合自身的业务场景来选型。
以此表来总结四个产品的竞争对比,优良中差来评级,当然,没有差的,毕竟都是行业主流的产品。业务级别的流量追踪,产品选型,需结合自身的业务场景来选型。
希望能帮助到您更有效的管理微服务,有快速的定位问题,做出最准确的判断哦。
原文:https://dzone.com/articles/are-you-tracking-kubernetes-applications-effective
-
云和安全管理服务专家


