
-
Ceph 使用 22TB Spinners 实现 40GiB/s S3 吞吐量 – 第一部分
Pawsey 超级计算研究中心为澳大利亚和国际研究人员提供跨众多科学领域的综合研究解决方案、专业知识和计算基础设施。Pawsey 主要将 Ceph 用于对象存储,其 Acacia 服务可提供数十 PB 的 Ceph 对象存储。Acacia 由两个生产 Ceph 集群组成:一个 11PB 集群支持常规研究,另一个 27PB 集群专门用于射电天文学研究。
这次的测试目标之一是评估 OSD 主机的不同部署架构:单台 1U 服务器,连接到 60 个外部盘( SAS 独立盘柜)。
下面,我们首先确定了一些初始问题,从而开始我们的测试工作。
- 在定义密集节点和相对较小的 NVME 所需的定制配置时,OSD drivespec 的性能如何?
- LED 控制等仪表板功能是否能与外部机箱配合使用?
- 为 RGW 实例使用虚拟机时是否有注意事项?
- 不同的 EC 配置文件在处理简单的 GET/PUT 工作负载时性能如何?
- 密集节点是否存在部署和管理问题?
- Ceph 面板处理密集 OSD 节点的效果如何?
正如我们所看到的,这些问题涵盖了各种各样的场景,因此,我们将分成三篇文章来描述,内容分别如下:
- 安装、管理和架构验证
- 性能深入探讨
- 扩展 RGW 实例
概 述
下面是环境和一些关键性能结果的展示。
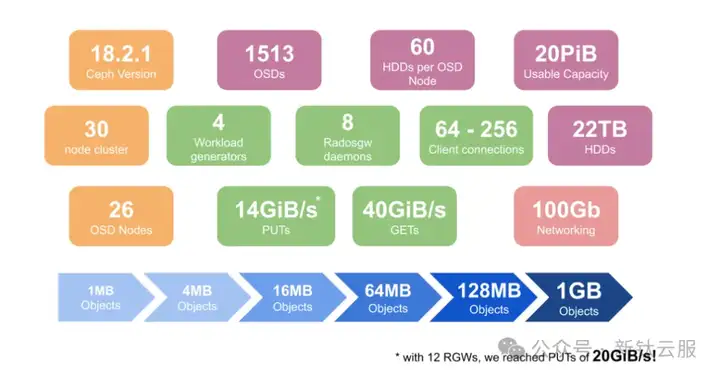
安装、管理和架构验证
01部 署
请注意,在 18.2.1 之前,ceph-volume 无法使用外部机箱提供的多路径设备。如果遇到问题,请检查您的 ceph 版本和 device-mapper-multipath 的使用情况!
我们面临的第一个挑战是 OSD 配置。block.db 分配的默认值基于 OSD 的容量(在我们的案例中为 22TB)。但是,每个 OSD 节点只有 4 x 1.6TB NVMe 硬盘,因此无法使用默认值。相反,我们使用了一个配置文件,该文件明确定义了 block.db 的空间以及 OSD 与 NVMe 驱动器的比例。
service_type: osd service_id: aio-hdds placement: host_pattern: storage-13-09012 spec: block_db_size: 60G db_slots: 15 data_devices: rotational: 1 db_devices: rotational: 0问题解决了,但我们又遇到了第一个小插曲。我们发现,在 cephadm 中,向密集节点部署 OSD 可能会出现超时。在我们的案例中只发生了两次,但还是很烦人!Reef 中有一个修复方案,可以让 mgr/cephadm/default_cephadm_command_timeout 设置由用户定义,但这个方案要到 18.2.3 版本才会 “正式修复”。如果和我们的部署环境差不多,请记住这一点。
02管 理
随着集群的部署,我们的重点转向使用 CLI 和 GUI 管理集群。下面是我们核心内容:
- 每个节点上的大量 OSD 和守护进程将如何在用户界面上呈现?
- 用户界面对超过 1,500 个 OSD 的响应速度如何?
- 鉴于部署基于多路径设备,磁盘将如何表示?
- IDENTIFY(LED 控制)等工作流是否能与外部硬盘一起使用?
- 硬盘对维护和电源循环等正常操作有何影响?
好消息是,总的来说,用户界面能够很好地应对如此多的主机和 OSD,LED 控制也运行良好!不过也有几个问题。
部署 OSD 后,仪表板中的设备列表不再显示硬盘。这个问题可归咎于 ceph-volume 本身,它为 GUI 和 ceph orch device CLI 命令提供了支持。这方面的 tracker 是 63862(https://tracker.ceph.com/issues/63862)
在 OSD 视图中切换页面的速度很慢(3-4 秒)。您可以在 56511(https://tracker.ceph.com/issues/56511) tracker 中解决此问题的进展情况
还提出了一些用户体验改进措施:

如前所述,该硬件基于通过 SAS 连接到 60 硬盘盒的 1U 服务器。虽然 SAS 与 Linux 的连接不是问题,但我们还是发现了一些相关问题,希望大家能牢记。
在启动时,如果主机比机箱先进入 “就绪 “状态,LVM 就无法激活 OSD 使用的逻辑卷。结果就是大量 OSD 处于停机状态。
Ceph 完全不知道机箱硬件的健康状况。在我们的电源循环测试中,有两个机柜出现了故障。对于 Ceph 来说,这表现为 OSD 处于离线状态,但直到检查机箱上的状态指示灯时才发现根本原因!
最后,在数据分析过程中,我们遇到了一个问题,即我们的监控报告比 warp 工具报告的投入运行次数要高得多,因此很难将 Ceph 数据与 warp 结果进行核对。
我们提出了 65131
(https://tracker.ceph.com/issues/65131)
tracker 来探索问题所在,并找到了罪魁祸首:multipart upload。对于大型对象,warp 客户端使用multipart并行操作,而 Ceph 会将每个 “part upload “报告为单独的 put 操作,从技术上讲确实如此。问题是 RGW 没有一个相应的计数器来表示上传操作的整体完成情况,因此无法轻松调和客户端和 RGW 的视图。
03架构验证
由于 OSD 节点是单插槽服务器,我们的初始策略是使用虚拟机来托管 RGW 守护进程,将尽可能多的 CPU 留给 60 个 OSD 守护进程。下面我们将验证这一方案。
鉴于 PUT 工作负载通常要求更高,我们使用了一个简单的 4MB 对象工作负载作为测试。下图展示的结果很差。连 2GiB 的吞吐量都无法提供,这表明设计中存在重大瓶颈!
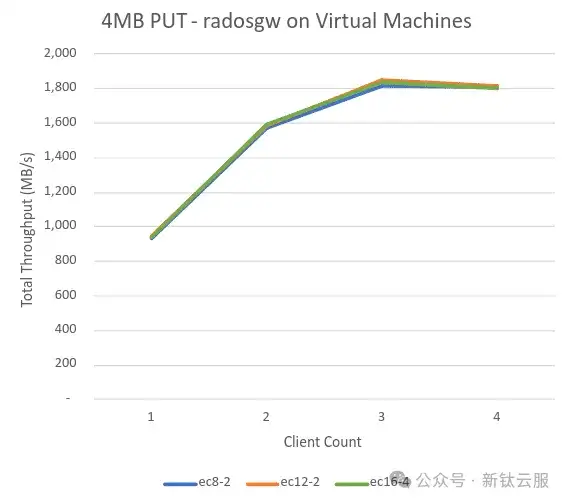
Ceph 性能统计完全没有发现问题,考虑到硬件情况,这一点也不足为奇。罪魁祸首不是 Ceph,而是托管 RGW 守护进程的管理程序的 CPU 和网络限制!
通过观察 OSD 的 CPU 使用情况,我们发现尽管每台主机上有 60 个守护进程,但 OSD 主机根本没有受到任何 CPU 压力。接下来,我们立即切换到 RGW 并置策略,将 RGW 守护进程迁移到 OSD 主机上。我们还借此机会将工作负载生成器配置到了 Ceph 索引节点上。现在,同样的测试提供了一个更合适的方式。
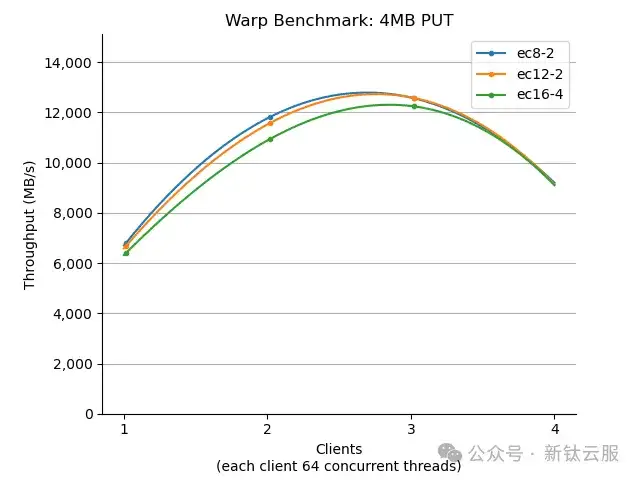
如我们所见,采用相应的策略后,PUT 吞吐量提高了 7 倍!
这是我们的首次成功,并将影响 Pawsey 的生产部署,使生产环境的效率大大提高。
在下一篇文章中,我们将深入探讨集群在各种对象大小和擦除码(EC)配置文件下的性能,会包含大量的统计数据图表。
如有相关问题,请在文章后面给小编留言,小编安排作者第一时间和您联系,为您答疑解惑。
云和安全管理服务专家


